下一篇: (準備中)
在上一篇教學,講了如何設置ML-Agents,在進到下一篇教學前,我想再另外補充一下,讓各位透過實作,體會ML-Agents到底是什麼。
這篇會帶各位建立一個小遊戲,並實際讓ML-Agents學習如何作為玩家操作遊戲。這篇不會做講解,只會告訴各位每個步驟,程式也直接整個給各位,這只是先讓各位有個體驗 (我也沒時間打太多內容w)。
首先,在我們上次建立的專案中設置好場景、玩家、目標。這邊物件的Scale沒有特別講的話都不要改,等一下程式才不會有問題。
新增物件後先將Transform重置,有時候新物件的位置不在原點上。
Plane:
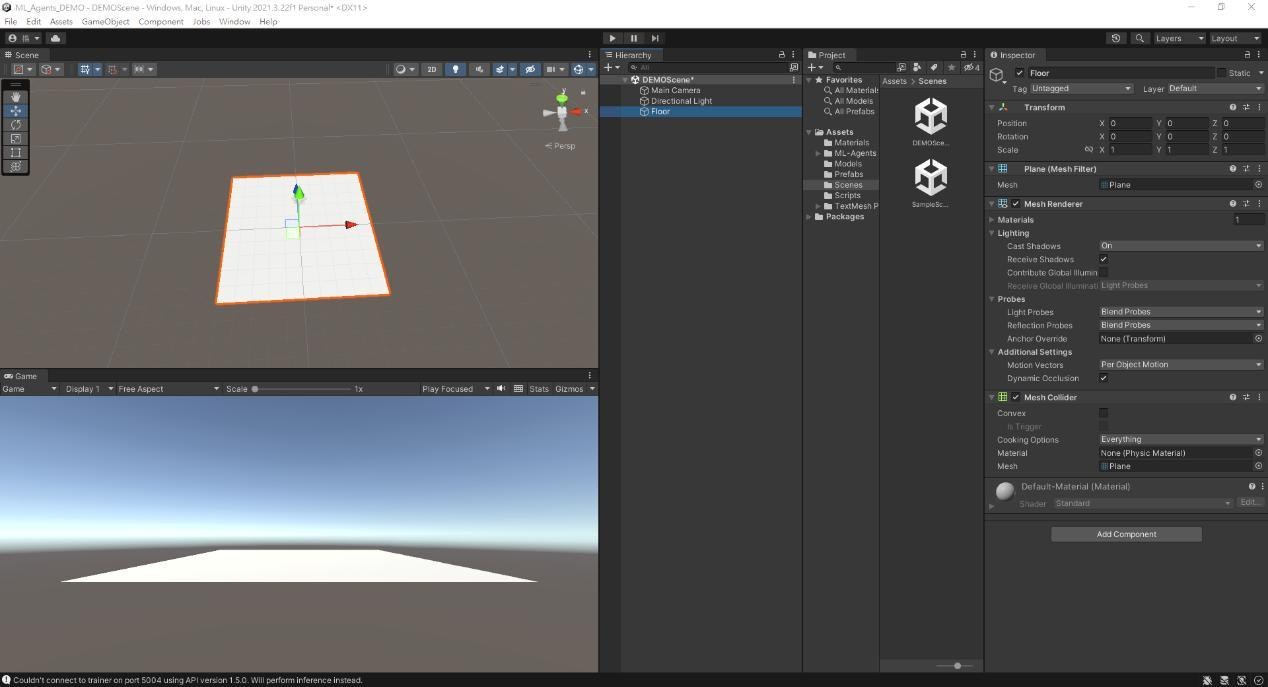
這邊將平面命名為Floor,做為玩家移動的平台。
Cube:
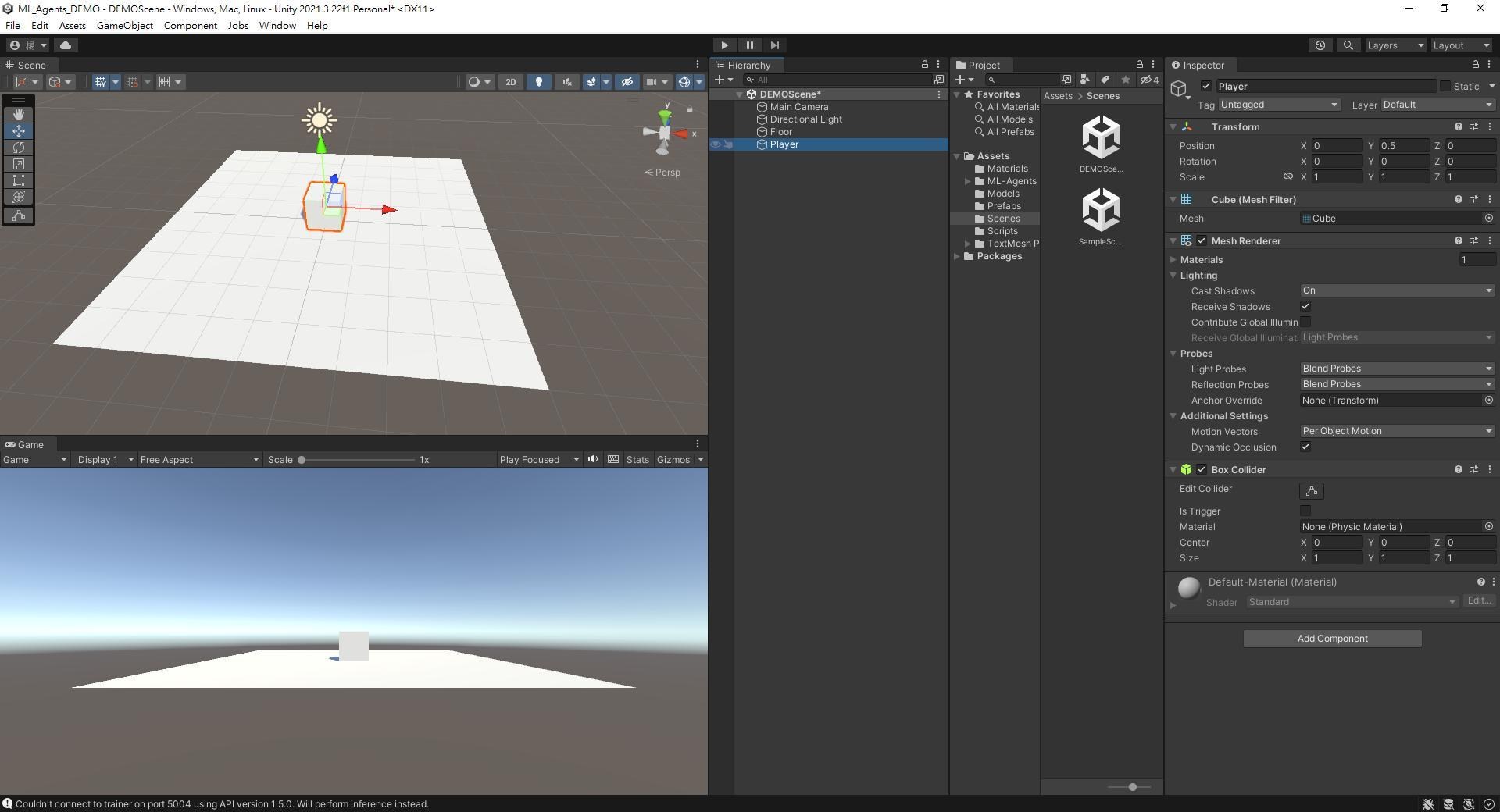
新增一個Cube,命名為Player,做為玩家。
Sphere:
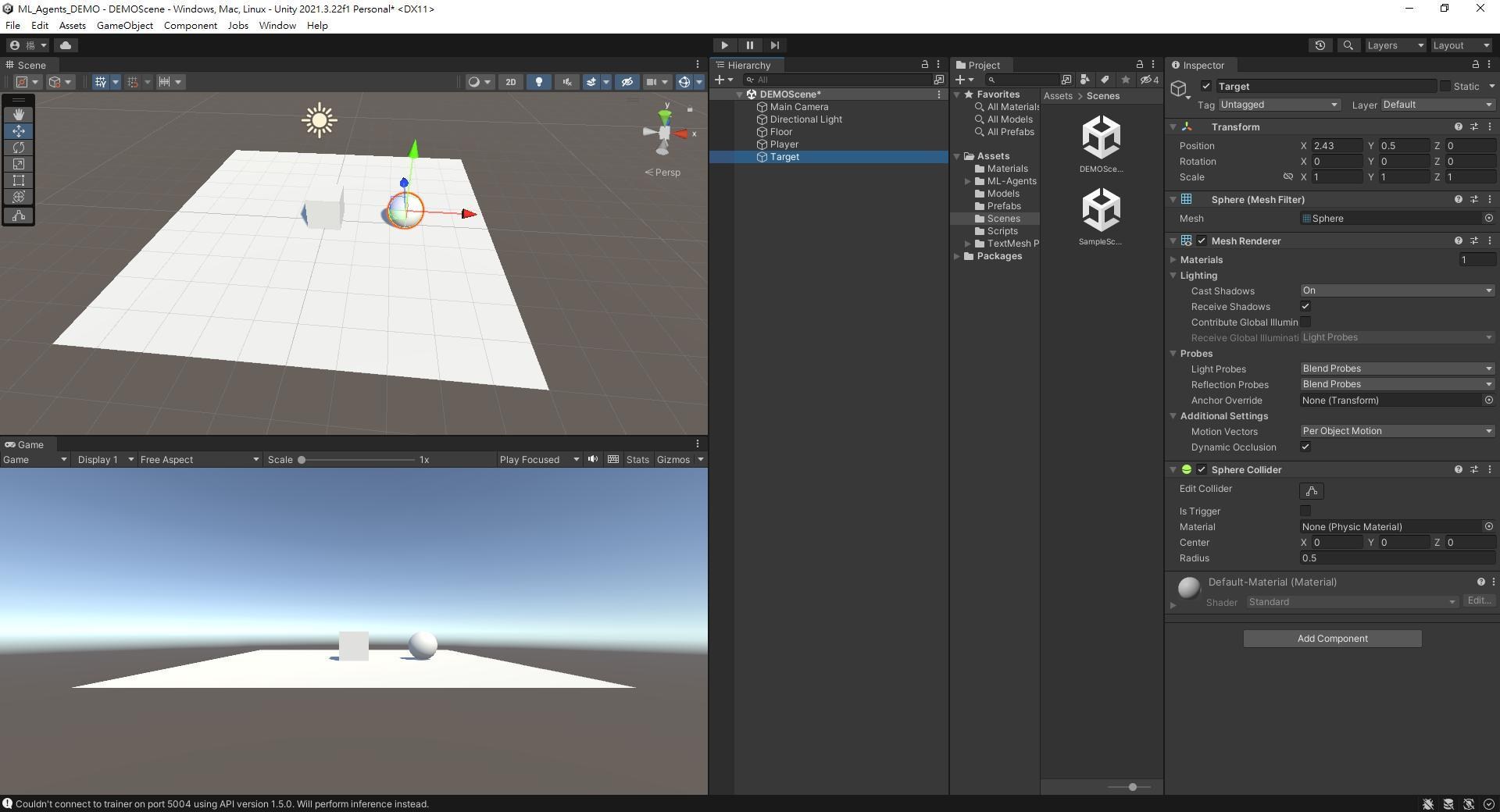
新增一個Sphere,命名為Target,這是玩家要移動的目標。
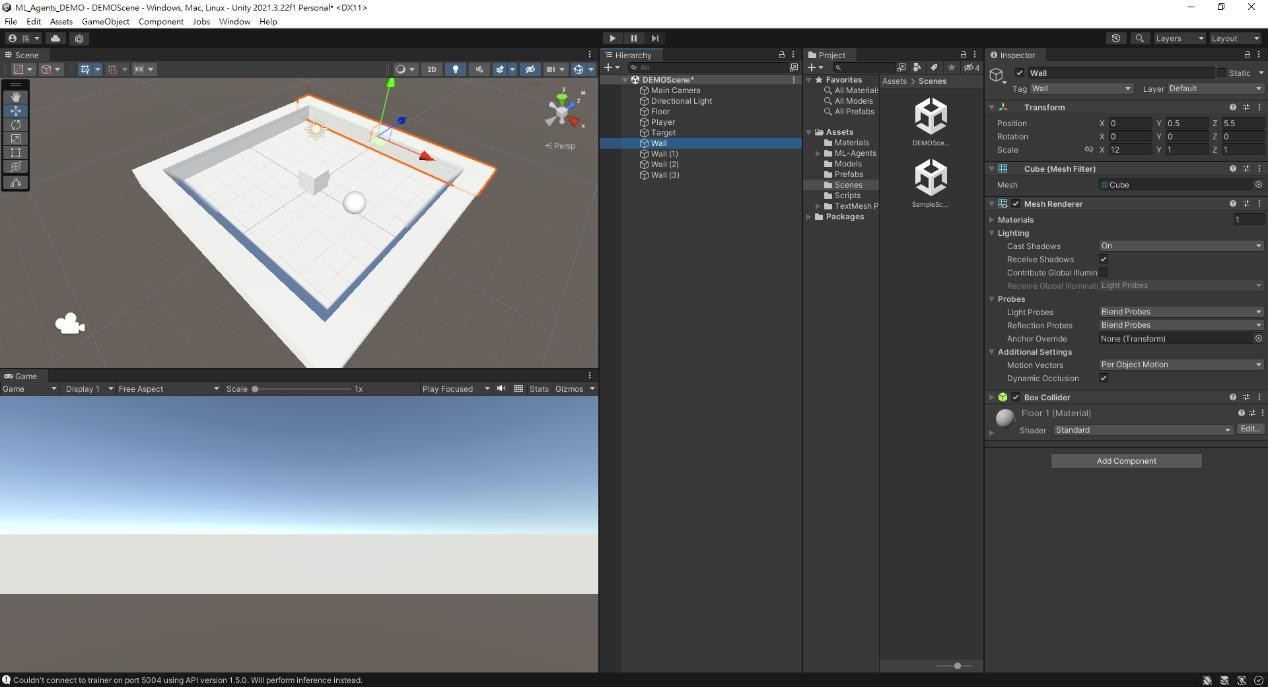
新增4個方塊,命名為Wall,調整Scale和位置,限制玩家活動範圍。
這邊可以透過Material幫物件上色,比較方便識別。
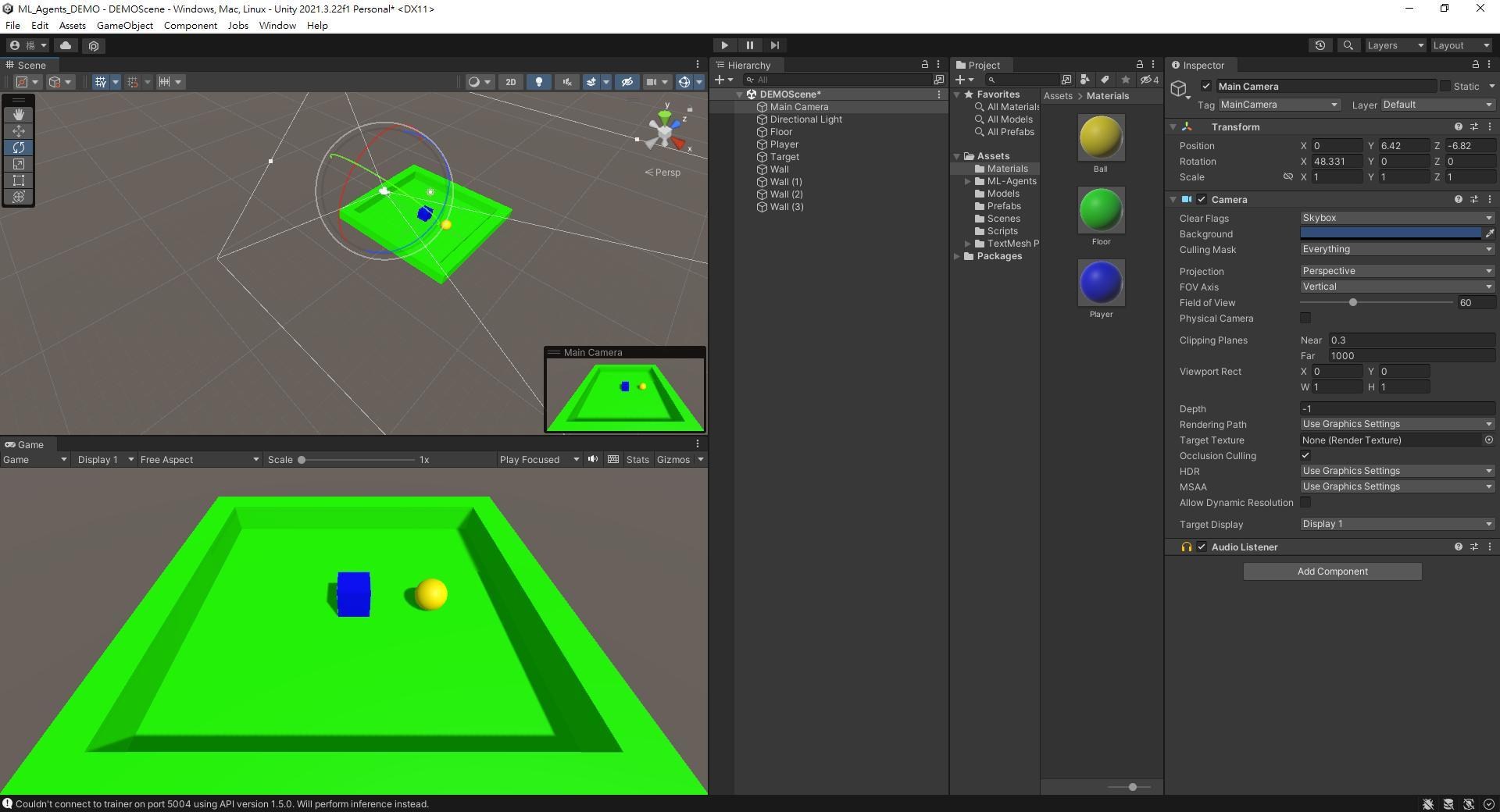
簡單調整一下Camera位置和角度。
程式檔案連結:
將程式加入Player。
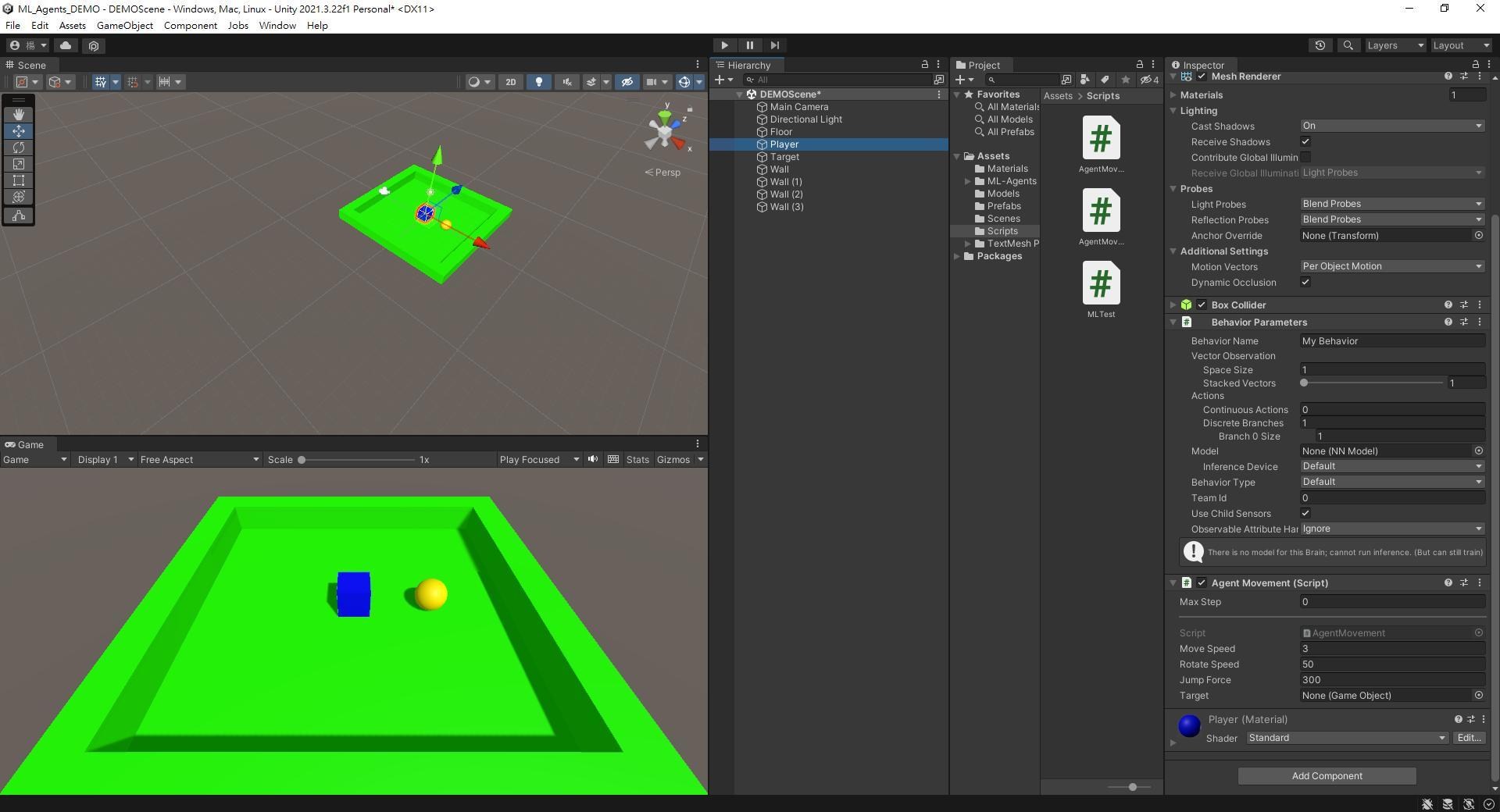
在Player的Component加入ML Agents -> Decision Requester。
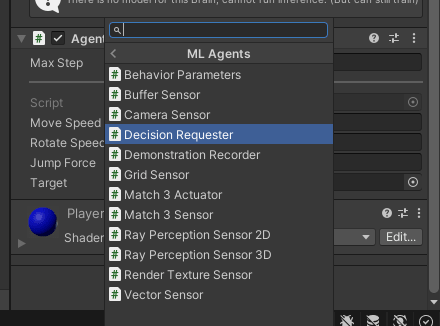
在Player的Component加入Physics -> Rigidbody,並勾選Is Kinematic。
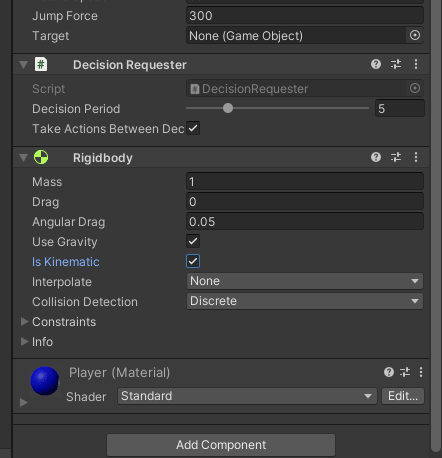
修改Player底下Behavior Parameters中Vector Observation的Space Size為6, Actions的Discrete Branches設為2,Branch 0 Size與Branch 1 Size設為3。
將Target物件拖進程式碼底下的Target欄位。
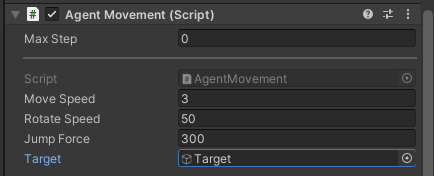
新增兩個Tag,分別是Target和Wall。
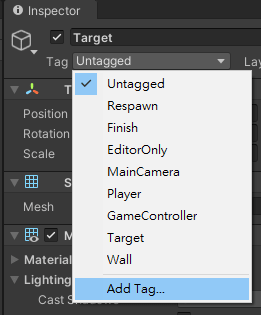
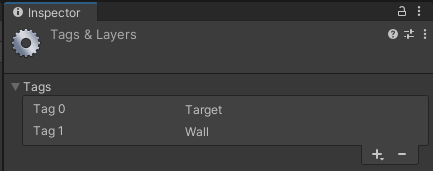
將Target物件的Tag設為Target。
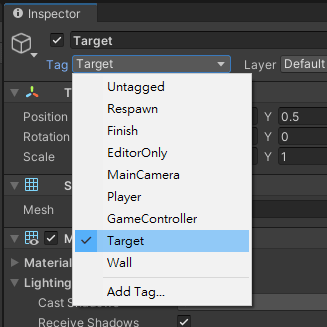
將全部Wall物件的Tag設為Wall (可以全部選起來一次改)。
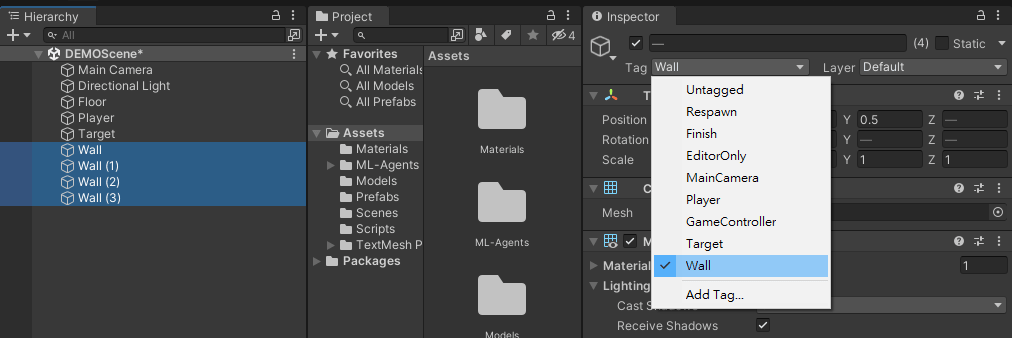
將Target物件下Sphere Collider的Is Trigger打勾。
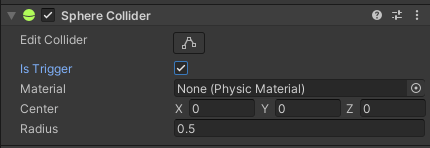
把全部Wall物件下Box Collider的Is Trigger打勾 (可以全部選起來一次改)。
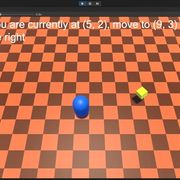
這時候按下Play按鈕,遊戲開始執行後應該要能夠看到玩家 (方塊) 和目標 (圓球) 出現在場景內的隨機位置,這時我們可以透過方向鍵來操控玩家,控制玩家前後左右移動。玩家在碰到球或是牆壁,或是放置超過10秒後,場景就會重置。
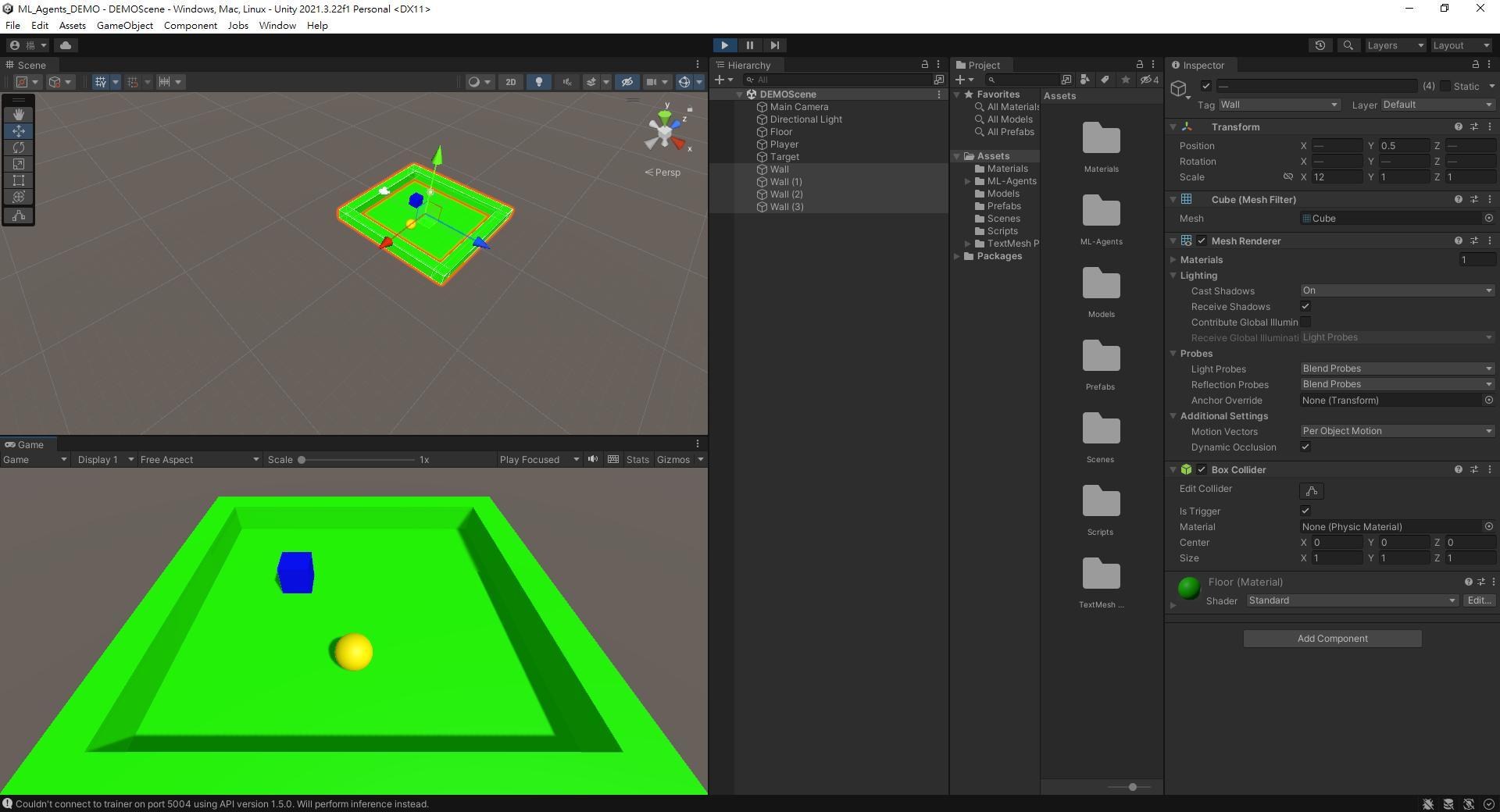
到這邊沒問題的話,就可以先來簡單測試一下ML-Agents。
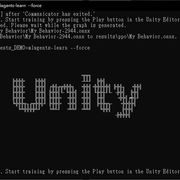
Unity如果還在Play狀態,先停止。照著上一篇的方式打開專案資料夾底下的Python虛擬環境,輸入mlagents-learn --force。
看到這個畫面後,回到Unity按下Play。
成功的話就能在Python虛擬環境視窗看到這個畫面,再去看Unity,可以看到玩家自己動了起來,這時玩家的動作會是隨機的,看起來就是在原地抖動。
這邊檢查一下Unity除錯視窗,不應該回報任何錯誤。
如果就這麼放著幾分鐘,應該可以看到玩家有幾次偶爾成功吃到目標,如果訓練得夠久,Agent就可以表現得不錯了,但是只透過一個Agent來訓練的效率不高,這邊可以透過同時訓練多個Agent來提高訓練效率。
先在Unity停止Play,接著在Python虛擬環境按下Ctrl + C,停止訓練 (這邊要是沒有按Ctrl + C,過幾十秒後一樣會timed-out停止)。
新增一個空物件,這邊命名為Environment,確保空物件的座標原點和世界座標原點相同。
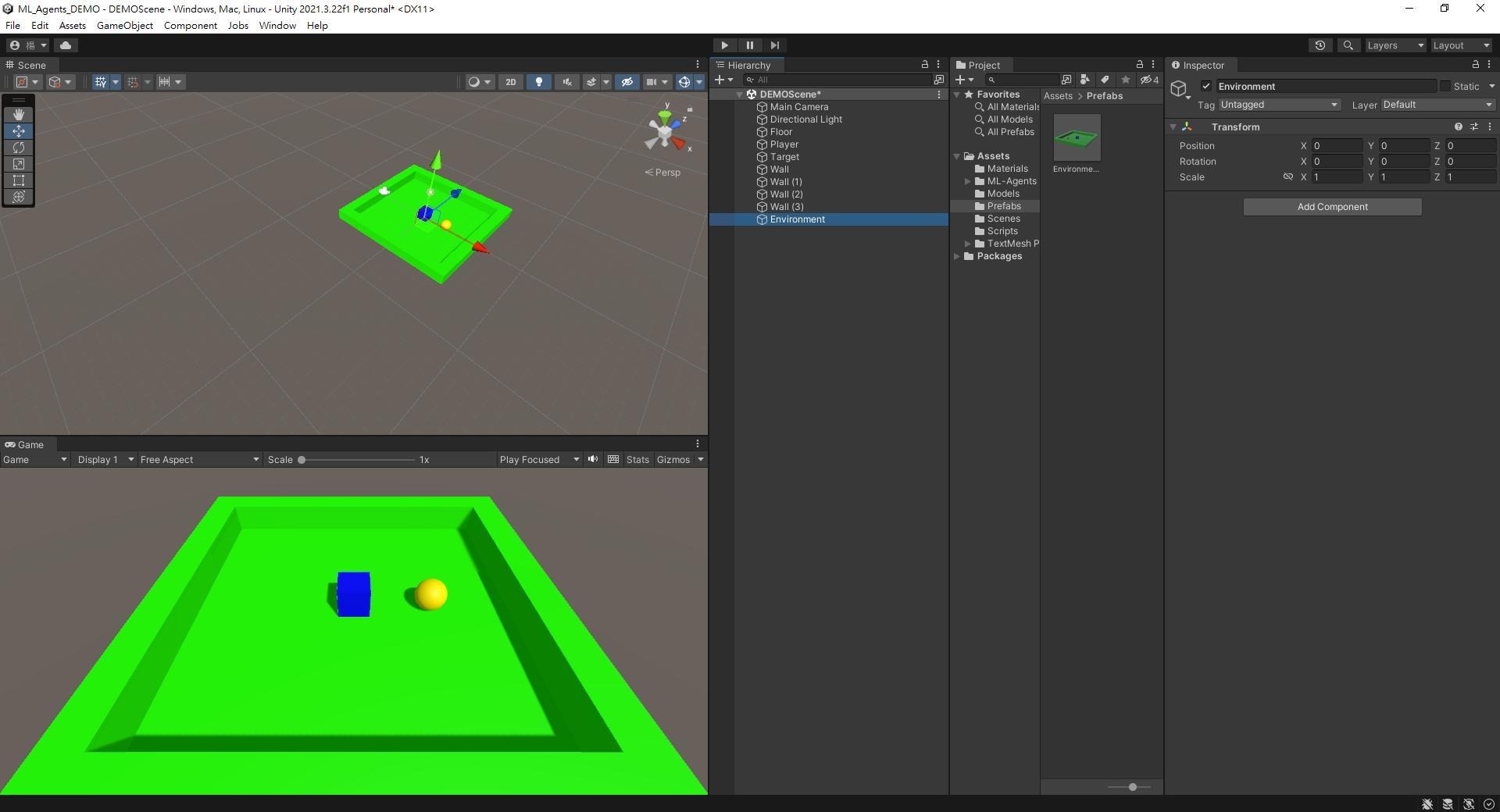
將所有場景中的物件拖入這個空物件底下 (不包含Camera和Directional Light)。

將整個物件拖入Assets,成為Prefab。
接著複製多個場景,數量大概25個就夠了 (Ctrl + D可以在原地複製物件)。
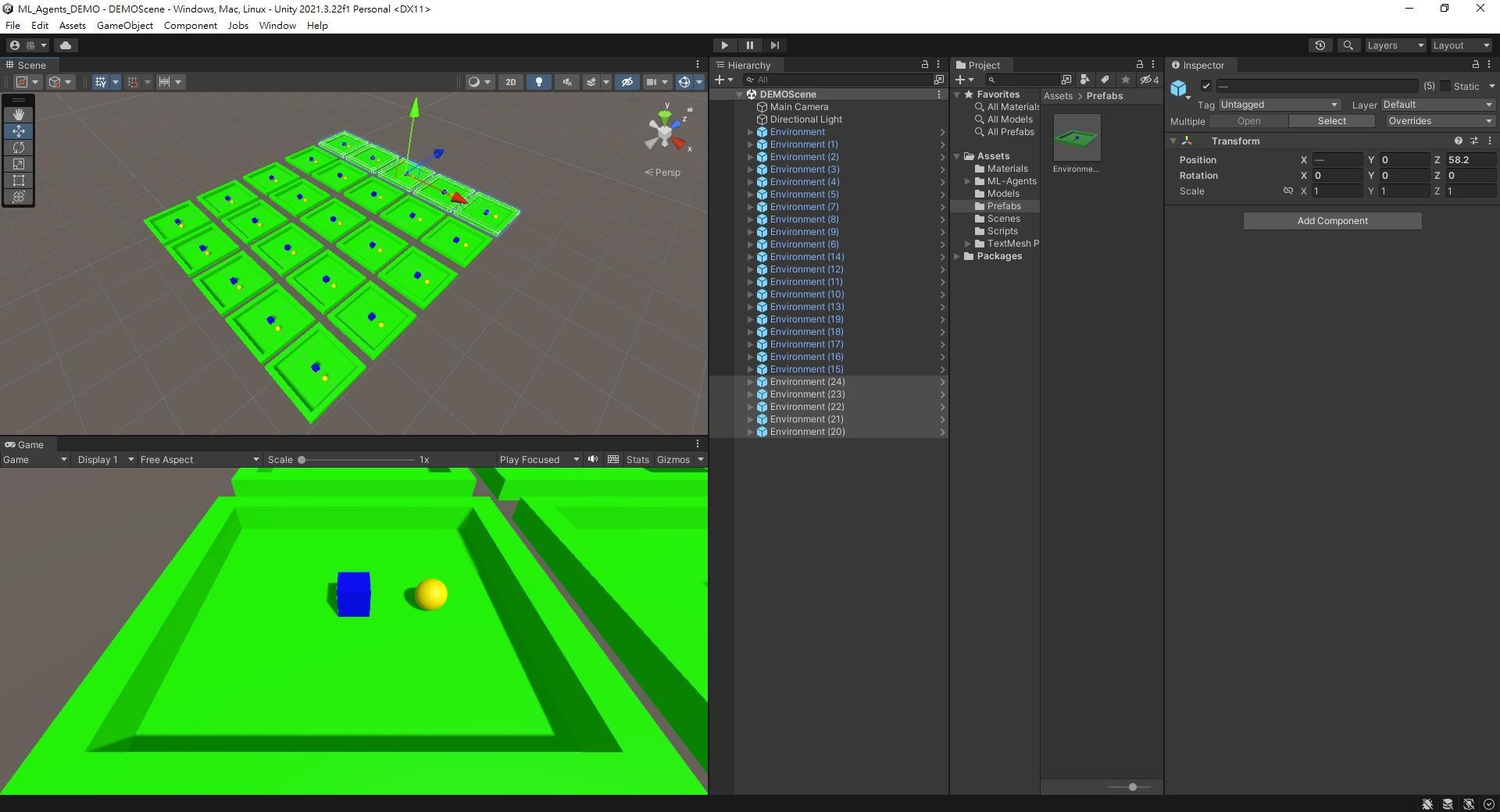
完成後看起來像這樣。
這時再重複之前的動作,輸入mlagents-learn --force,在Unity按下Play。
這時應該要看到Unity中所有的Prefabs都在進行訓練了。隨著時間過去,大概不到5分鐘就能看到Agent已經能把玩家操控得不錯。
等待的期間,我們可以再開一次Python虛擬環境 (千萬不要關掉現在已經打開的),這次輸入tensorboard --logdir results。在開始訓練的同時,會在專案底下的results資料夾儲存訓練的各種資料,這邊使用TensorBoard來視覺化這些資料。
接著在瀏覽器輸入視窗顯示的網址。
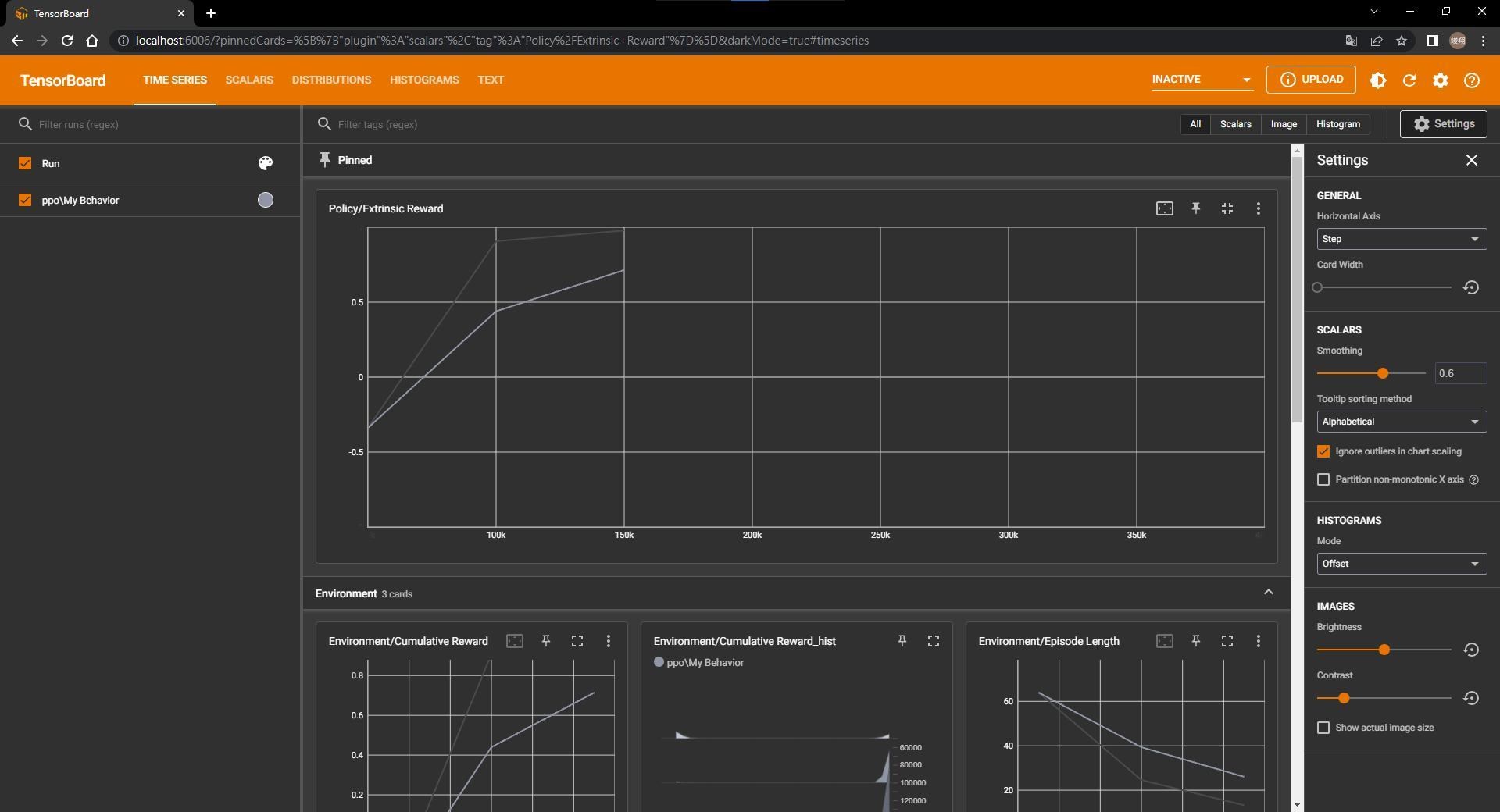
這邊就是將訓練狀態可視化的圖表,我們可以將重點放在Policy/Extrinsic Reward上,這邊可以看到Agent獲得獎勵的狀態,獎勵在-1到1之間,獎勵越高,代表Agent訓練的越好。這邊的獎勵是透過程式碼設定的,之後的教學會實際講解如何寫這些內容。
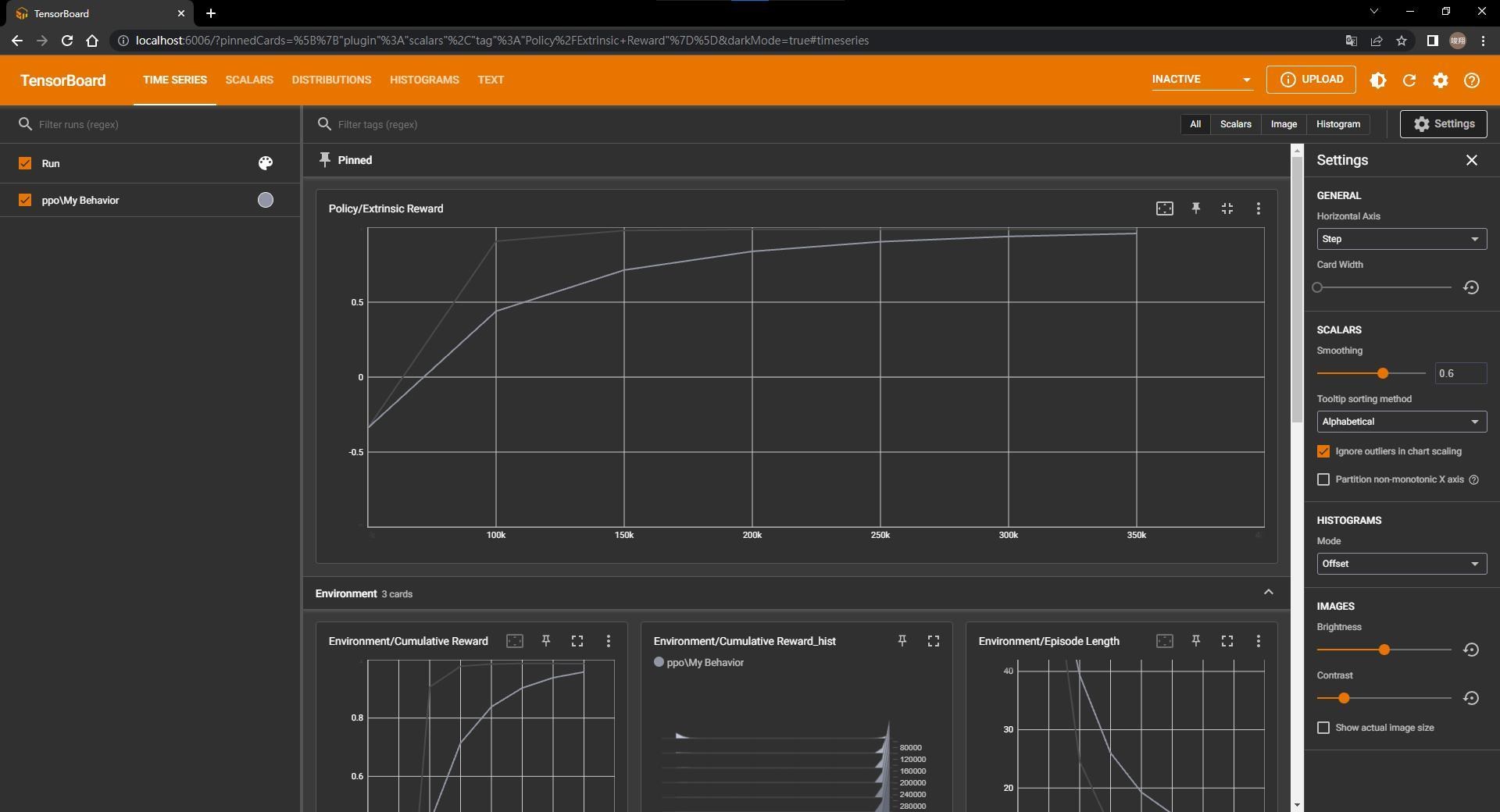
過一段時間之後,大約150k的位置就可以看到曲線非常接近1 (深色線是實際值,淺色是平滑化的值),代表Agent已經訓練得差不多了 (這邊我有在程式碼加入時間懲罰,所以不可能到達1)。
這時我們可以將訓練好的模型實際丟到Unity,讓Agent執行。
先依照之前的步驟停止訓練。
複製專案跟目錄底下的/results/ppo/My Behavior.onnx,貼上在專案底下的Assets資料夾。
回到Unity,可以在剛才貼上檔案的位置看到訓練好的模型。
只留下一個Prefab,其他的都選起來把狀態設為不啟動 (或沒有要再訓練的話,直接刪除也行)。
將模型加入Player中Behavior Parameters的Model。
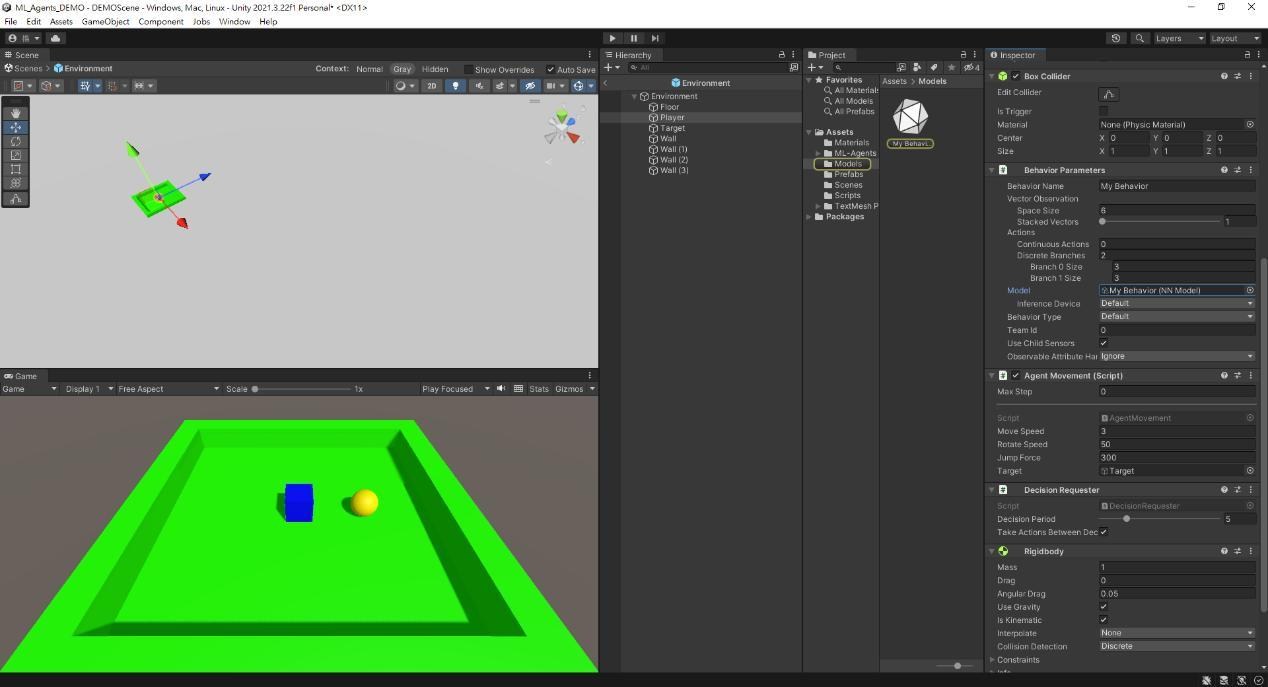
接著直接按下Play,就可以看到遊戲中的玩家幾乎沒有遲疑地朝著目標前進,這邊Agent可能還是會有一點奇怪的行為,只要訓練得夠久,基本上就沒問題了。
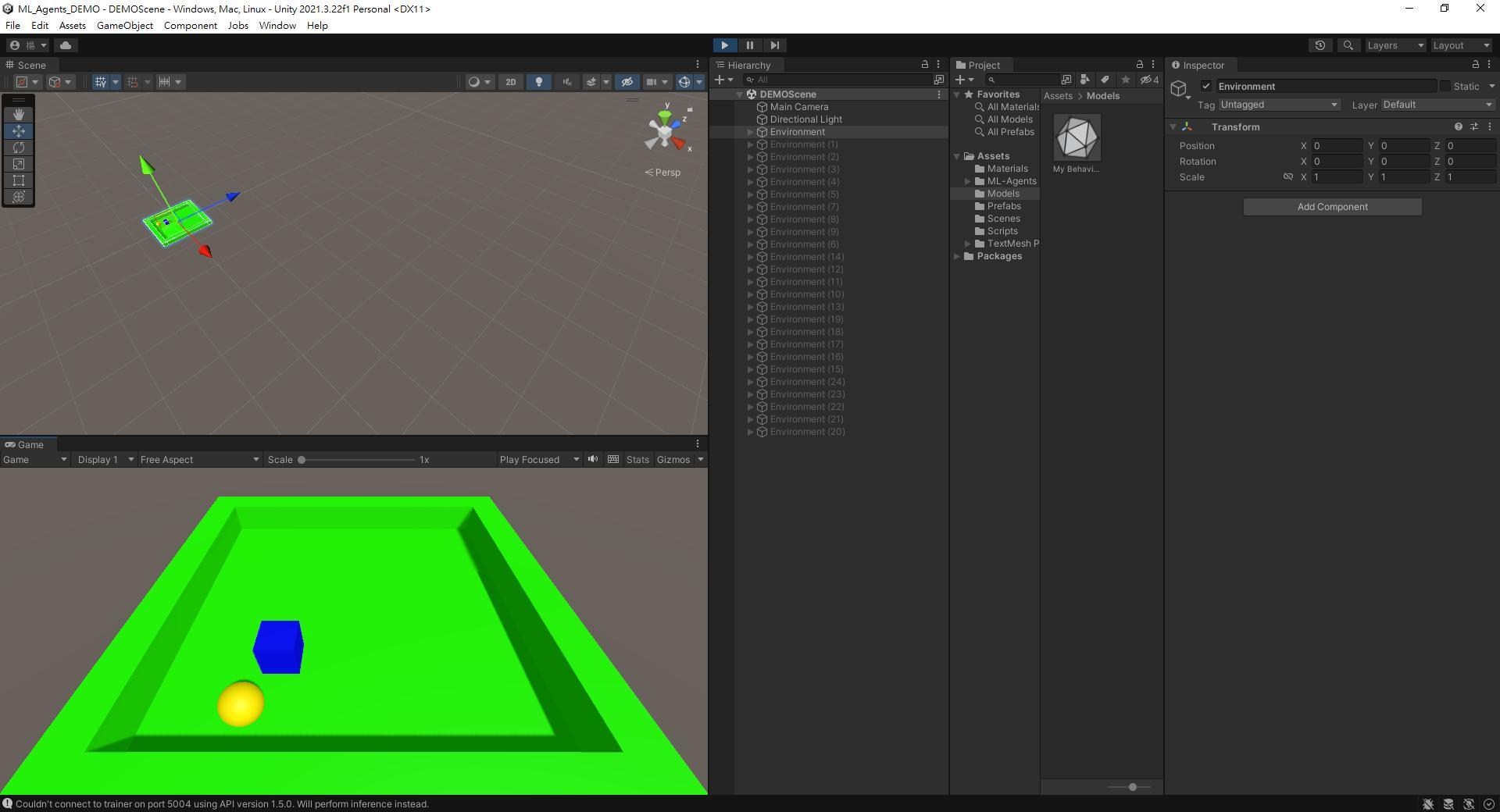
ML-Agents的安裝和測試到這邊應該就真的告一段落了,接下來會比較詳細講解ML-Agents,並設計一個較為複雜的遊戲來訓練Agent,在更之後的教學,會帶各位嘗試一些不同的Agent輸入和輸出,也就是用一些不同的輸入資料來訓練Agent還有讓Agent進行控制。
如果你對Unity相當不熟悉,可以參考文章開頭的Unity相關創作資料夾,裡面的第一篇有講到如何製作出一個和影片中差不多的遊戲。
謝謝各位看到這裡,有任何問題或建議都歡迎在下方留言或私訊。
在寫這篇的同時又多了好多事情要處理,下次再發相關創作可能真的又要等上一段時間了。希望不會像這個系列第一篇和第二篇那樣隔了半年www
如果有人希望能快點看到之後的內容,也歡迎留個訊息或是給GP支持,說不定我會想辦法擠出時間來寫w
話說回來,把這些東西寫成文章花的時間真的是自己操作這些內容的好幾倍啊...
這篇到這邊真的結束了,謝謝各位,也希望有興趣的人可以支持接下來的內容(不知道什麼時候會出現就是了w)。