# 用來操作文件目錄 import os # 向網頁發請求 import requests # 分析 HTML 的工具 from bs4 import BeautifulSoup # 載入 selenium 模組,模擬使用者操作瀏覽器 from selenium import webdriver from selenium.webdriver.chrome.options import Options # (要先下載執行檔)設定 chromedriver 執行檔路徑 options = webdriver.ChromeOptions() options.chrome_executable_path = "/貼執行檔的路徑/chromedriver-mac-arm64/chromedriver" # 建立 driver 物件實體,用程式運作瀏覽器 driver = webdriver.Chrome(options = options) driver.get('https://www.shonenjump.com/j/haikyu-jack/poster/') # 貼要爬的網址 #存網頁的完整 HTML 内容 html = driver.page_source #先印出來觀察 HTML print(html) |
截一小段 HTML 來看
<img src="/j/haikyu-jack/poster_thumb/20.jpg" loading="lazy" alt="烏養一繋" class="memberImg" data-v-d9e559b8="">
src= “要抓的圖片來源”
alt=“預設檔名”
測試 print 人名
| for img in imgs: try: print(img['alt']) except: pass |

看一下檔名對應圖片來源
| for img in imgs: try: url = img['src'] name = img['alt'] print(f'{name} - {url}') except: pass |

開始存網頁的圖片
觀察圖片來源網址:https://www.shonenjump.com/j/haikyu-jack/poster_thumb/1.jpg
url 變數中把藍底處網址加上去
#用 BeautifulSoup 解析 HTML soup = BeautifulSoup(html, 'html.parser') #查找所有 <img> 標籤 imgs = soup.find_all('img') for img in imgs: try: url = 'https://www.shonenjump.com' + img['src'] #從解析後的 HTML 中提取圖片的 URL filename = img['alt'] #設檔名 resp = requests.get(url) #取得圖片的內容 img_data = resp.content os.makedirs('haikyu!!', exist_ok=True) #建立資料夾 haikyu!! with open(f'haikyu!!/{filename}.jpg','wb') as f: #圖片內容寫入 jpg 中 f.write(img_data) except: print("圖片下載失敗!") |
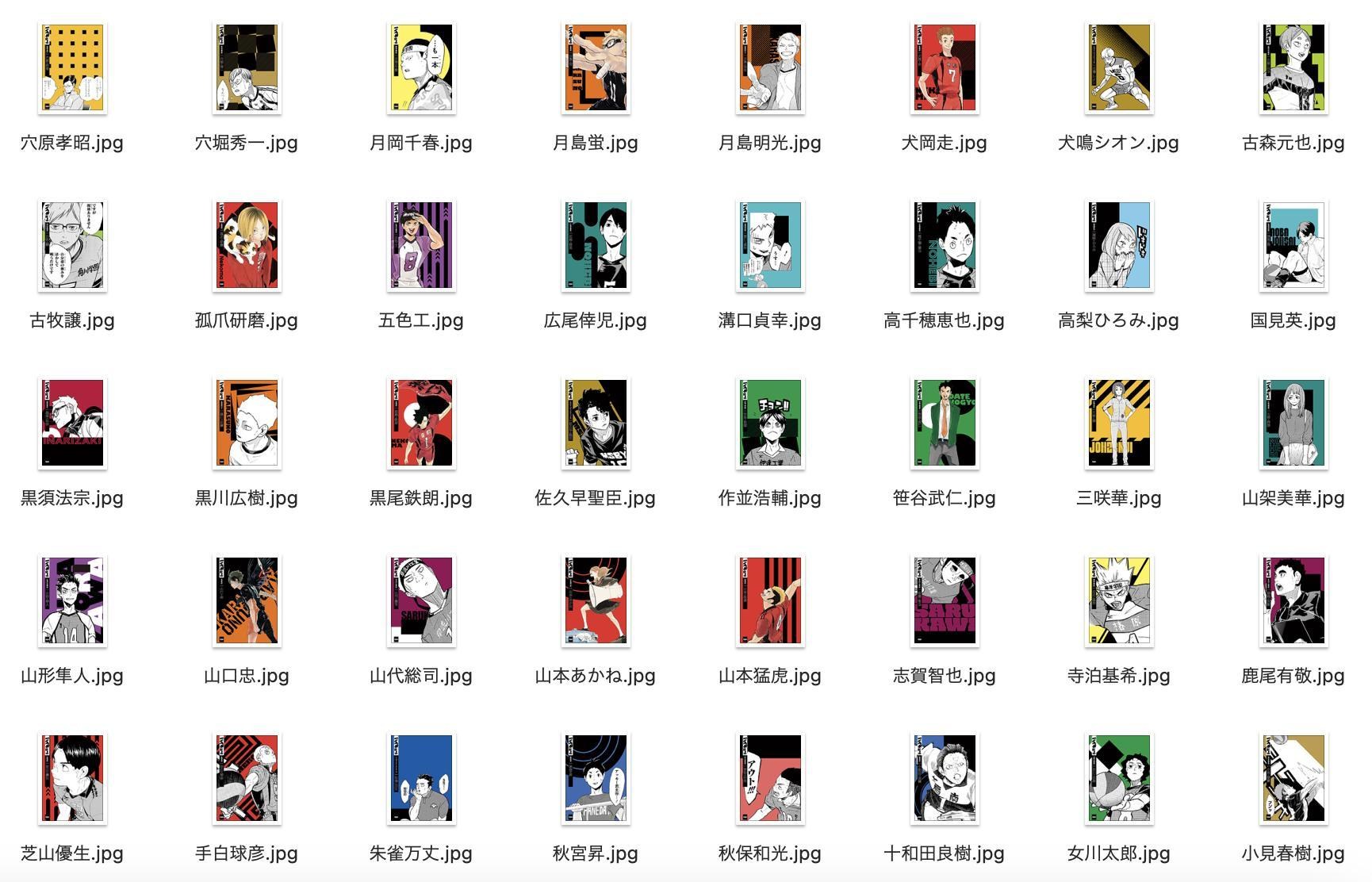
完成,但只是存了一堆縮圖 : 3
實作遵照: