上篇的只要文章中的程式碼即可運行
這篇相較上篇的程式碼比較完整且複雜
所以獨立用一篇來記錄這樣
用Scrapy去爬巴哈姆特場外休憩區的標題跟預覽內文
並輸出csv檔
連結中有附上其他人的教學
我主要是來這裡紀錄自己的東西
要跑專案的話下載專案檔後
開啟CMD小黑窗
cd指令到專案資料夾位置
然後pip install -r requirements.txt安裝相關套件
最後再輸入Scrapy crawl BH即可運行
可以設定要爬多少頁,我試過至少可以爬百頁以上
不過過度對巴哈伺服器發出請求會對巴哈伺服器造成影響
還在測試的程式碼,建議不要一次設定爬太多頁
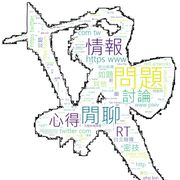
以下這是匯出成CSV的結果
因為標題太多字了,所以內文被標題遮住