主題
題目連結:
題目意譯:
你被給定一個大小為 m × n 的整數陣列 grid 以及一個大小為 k 的詢問陣列 queries。
請找出一個大小為 k 的陣列 answer 使得對於每一整數 queries[i],你從矩陣中最左上角的格子出發並重複以下步驟:
如果 queries[i] 嚴格大於你現在位於的格子之數值,則在你第一次到此格子時可以獲得一點點數。而你可以移動到四個方向上相鄰的格子:上、下、左和右。
反之,你不會得到任何點數,並結束此過程。
過程結束後,answer[i] 為你可以獲得的最大點數。注意到在每筆詢問你可以重複走到先前走到過的格子上。
回傳最後得到的陣列 answer。
限制:
m == grid.length
n == grid[i].length
2 ≦ m, n ≦ 1000
4 ≦ m × n ≦ 10 ^ 5
k == queries.length
1 ≦ k ≦ 10 ^ 4
1 ≦ grid[i][j], queries[i] ≦ 10 ^ 6
範例測資:
範例 1:
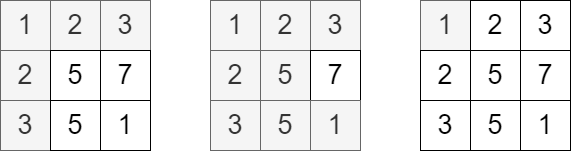
輸入: grid = [[1,2,3],[2,5,7],[3,5,1]], queries = [5,6,2]
輸出: [5,8,1]
解釋: 上圖顯示了在每一筆詢問中我們拜訪並取得點數的各個格子。
範例 2:
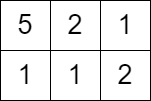
輸入: grid = [[5,2,1],[1,1,2]], queries = [3]
輸出: [0]
解釋: 我們沒辦法得到任何點數因為左上角的格子之點數已經大於等於 3 了。
解題思維:
可以看到對於每一筆詢問 queries[i],answer[i] 之值即為從矩陣左上角出發擴散到所有數值小於 queries[i] 之格子總數(記得把起點本身算進去)。也就是對於一筆詢問,我們可以從左上角進行一次廣度優先搜尋(Breadth First Search,BFS)來得到 answer[i]。
不過如果每一筆都要這麼做的話,時間複雜度最糟會是 O(mnk),不甚理想。
而我們可以看到如果先把 queries[i] 中的數值由小到大排序(不過原本的索引值要留著,因為 answer[i] 最終還是得求的),則如果我們先去對數值比較小的詢問值開始擴散,則後面對於比較大的便可以「繼承」先前的擴散。
不過由於先前擴張到的範圍之「邊界」(代表著當我們換成數值比較大的時候,這些「邊界」有可能會被擴張並包含進來可以被算成點數的範圍內)格子的數量依舊可以逼近 O(mn)(可以刻意造一個會產生類似皮亞諾曲線的測資。該曲線形狀參見維基),所以最差的時間複雜度依舊是 O(mnk)。
可以看到上面的問題是因為我們換成數值較大的 queries[i] 時,我們不知道可以擴張到哪裡(也就是不知道哪些 grid[i][j] 之值是小於 queries[i] 的)。
那麼我們一併把 grid 中的數字由小排到大就可以了,這樣一來在較小的 queries[i] 時最後停留的數字 grid[i][j](也就是說再繼續 grid[i][j] 之值會大於等於現在 queries[i]),則之後換成較大的 queries[i] 時便可以繼續之前的 grid[i][j] 看可不可以繼續往大的數字走。
不過這麼一來,我們擴張的範圍就不會只僅限於從矩陣最左上角開始了。現在這個作法會產生多個區域,而一旦這些區域擴張到彼此身上時將會合併成一個較大的區域。可以看到這個「合併後的區域」,其實就是原先有一個集合與另一個集合合併之後所得的集合。再加上我們只在乎集合的大小(因為 answer[i] 可以看做是左上角那個格子的「集合大小」)。
而談到集合之間的合併又只在乎集合大小(以及誰在或不在集合之中),便可以連結到併查集(Union-Find Set,參見這題的介紹)。因此我們可以使用併查集來處理這些擴張的「區域」並在它們擴張到彼此身上時「合併」。
這樣一來,時間複雜度就變成了 O(mnα(mn) + k),其中 α() 代表著反阿克曼函數(Inverse Ackermann Function),是經典的單次併查集操作之時間複雜度,在此不多做解釋。可以看到這個時間複雜度快了很多。
此次分享到此為止,如有任何更加簡潔的想法或是有說明不清楚之地方,也煩請各位大大撥冗討論。






