不得不說,最近隨著 SD的插件越來越多,真的覺得光光追進度就累到不行ΘωΘ
這幾天光去理解新插件的功能與使用就花了不少時間,比如 ControlNet 跟 Lora 的權重測試就可以花上不少時間~ 這部分我還在想要怎麼做出一張有個人風格的圖,或是符合個人表達的圖
總覺得還是要有點個人情感介入,才能比較好的投入AI繪圖的改良過程,不然單純就是丟詞擲骰子,總覺得很難投入精力(:з」∠)
這篇基本上比較偏個人的資料整理,要說有什麼硬知識~ 說真的,現在AI繪圖的文字與影片教學太多了,基本上只有想不想學,而沒有找不到資料,剩下的就是拚詠唱者對於構圖的理解+自訓練Lora~~ 不過呀,我倒是滿想去訓練一個"夏娜"的 Lora,這樣剛好可以把之前img2img的圖修得更貼近原畫風格,不過具體要什麼時候執行,就等我什麼時候進入zone吧.....畢竟,一想到要花的時間,就覺得懶癌發作
首先,還是先更新一些之前文章沒提過的"新"資訊吧(知道就跳過吧XDDD)
1. SD更新:
參考這篇文章(https://mnya.tw/cc/word/1953.html),主要是一些新插件、ControlNet 跟 Lora的使用都要更新SD版本才能使用;其中,命令指令的部分要下在放有stable-diffusion-webui 程式的資料夾,才能正常更新;弄錯資料夾是沒辦法更新的
2. Lora 的使用:
SD更新到最新版本後,可以去(https://civitai.com/)中找中意的Lora模式並下載下來,之後放在 SD資料夾中 models的Lora資料夾中,就可以在SD的UI介面中使用
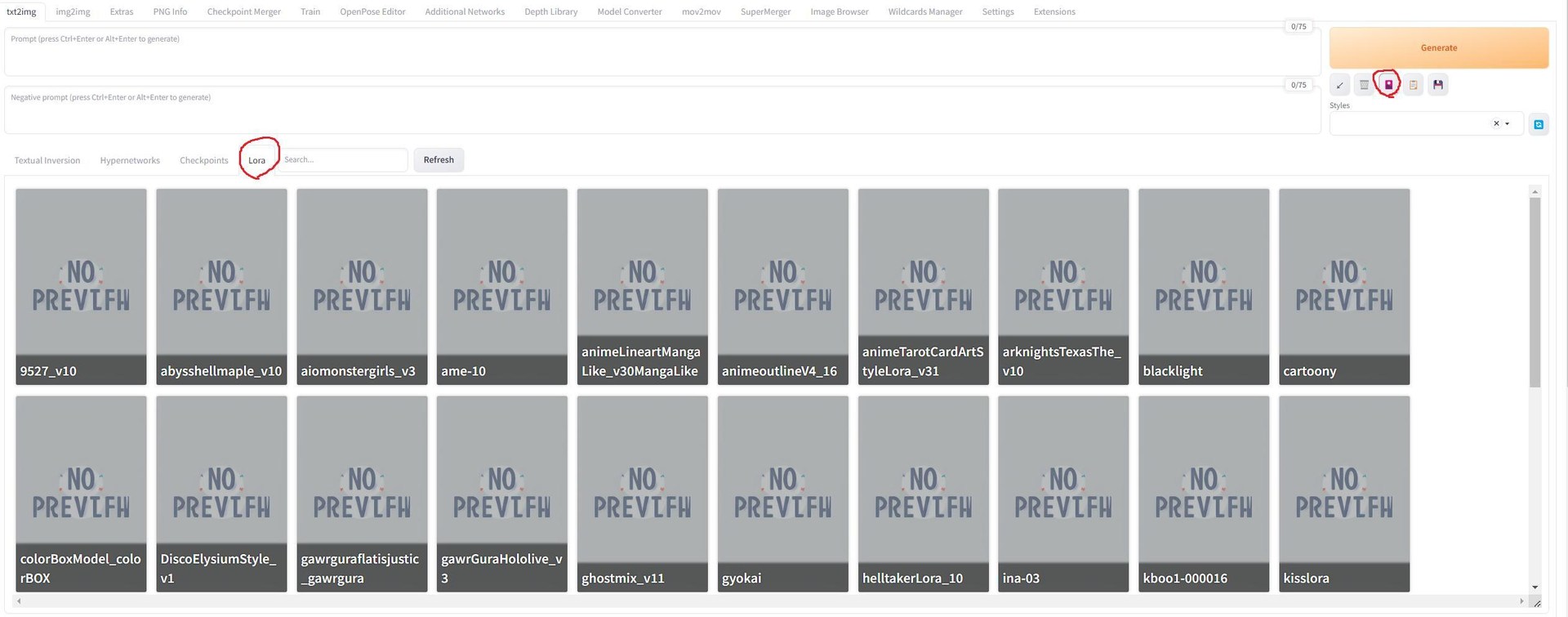
按 generate 下方洋紅色的圖標,就會出現下方的表單,找到Lora的項目,就可以使用; 使用權重與相應的 prompt 就參考Lora 作者提供的資料,一般作者在描述中都會提到建議的權重
3. 插件下載(可參考:https://www.ptt.cc/bbs/AI_Art/M.1681610455.A.501.html):
由於 SD的插件更新的實在是太快了,而且一些插件的功能太過於強大(比如:images-browser,100%建議裝);插件的安裝可以通過 install from URL

其中,github 會提供相關插件的下載連結,把連結複製並貼到第一欄就可以安裝
至於相關插件的使用教學,一般插件的作者會有註解;如果懶得看或看不懂註解,那就上youtube查吧XDDD 熱門的插件一堆人搶著做影片教學

4. Inpaint(局部修圖):
在 img2img中新更新的功能,是目前我用到現在最有感的功能(可能我SD用的少吧 ); 這功能可用筆刷去設定AI生成的圖要重新修復的位置(一個重骰XD),再重骰的過程還可以重新調整 prompt, CFG, denoising strength;比如我需要大改時,就會把CFG, denoising strength 調高,而等到骰到我要的效果,再針對細節調低CFG, denoising strength來微調
); 這功能可用筆刷去設定AI生成的圖要重新修復的位置(一個重骰XD),再重骰的過程還可以重新調整 prompt, CFG, denoising strength;比如我需要大改時,就會把CFG, denoising strength 調高,而等到骰到我要的效果,再針對細節調低CFG, denoising strength來微調
); 這功能可用筆刷去設定AI生成的圖要重新修復的位置(一個重骰XD),再重骰的過程還可以重新調整 prompt, CFG, denoising strength;比如我需要大改時,就會把CFG, denoising strength 調高,而等到骰到我要的效果,再針對細節調低CFG, denoising strength來微調
同時,圖的部分也可以只重骰被筆刷遮蓋的位置,這可以避免重骰的過程影響到整張大圖(說是不影響,但整張圖重骰時細節還是會稍微動到)
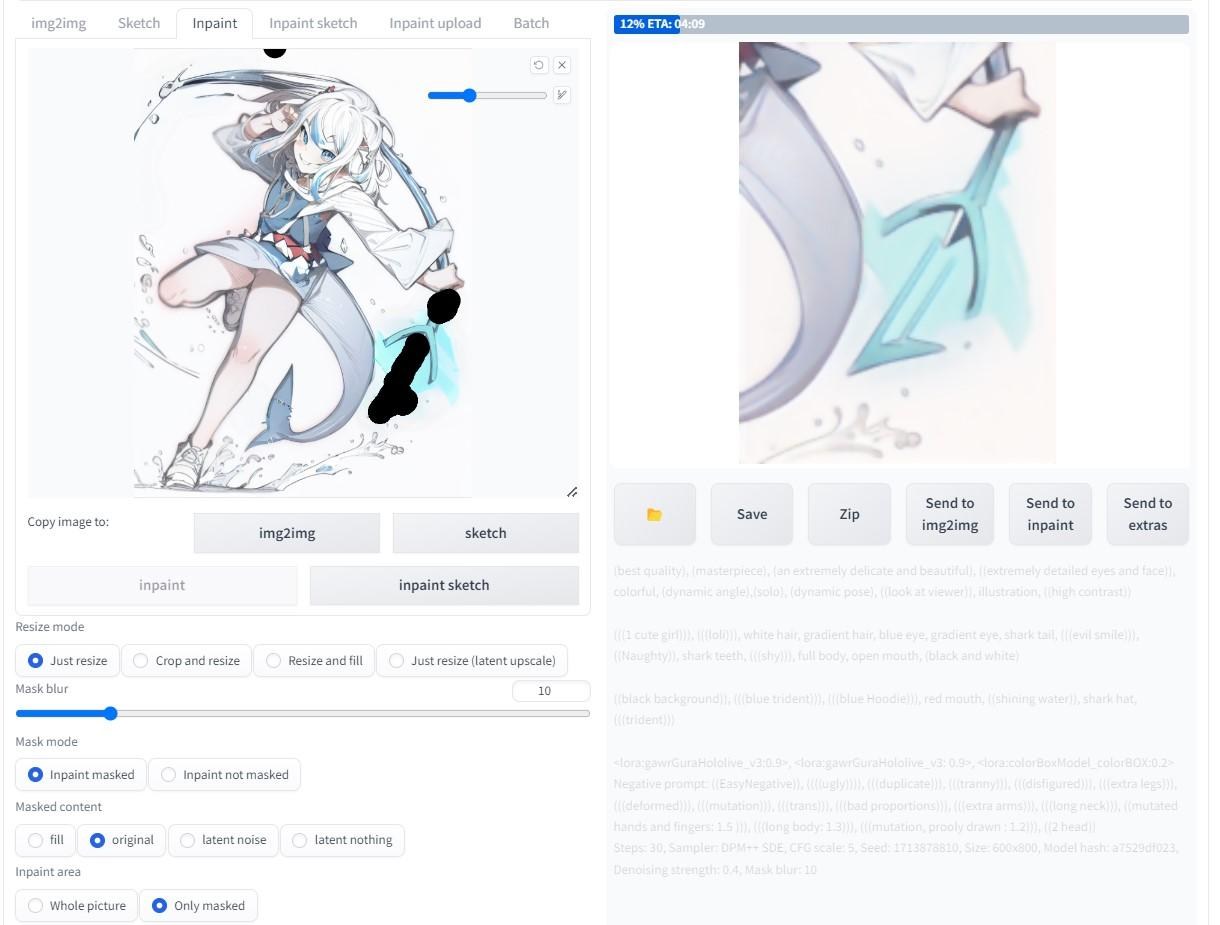
這邊就展示一張用 inpaint功能重新調整細節的過程:

真心覺得inpaint功能有夠好用;以前全部重骰,一些明明不錯的細節整個不見,一個苦;現在可以保留想要部分,只針對錯誤或不需要的細節進行微調,大幅AI做圖的精度與縮短作業時間
接下來就是來嘗試用 inpaint 功能來製作簡單的表情動圖吧✧(순_순)"
這個想法其實是出自之前我曾用手繪製作過的表情動圖,大圖可以看p站,主要是巴哈有上圖圖片大小限制(https://www.pixiv.net/artworks/88844669_內容上可能有點差別,但用到的圖檔是重複的)

原本我的想法是通過我本來就繪製好的草稿,用 SD 重繪後,我再整理GIF就好───── However~ 代誌不是像憨人想ㄟ那麼簡單ತωತ
即便我認為上面動圖的各草圖應該算是相似度高了,但如果每張獨立丟到SD中去生成,最後的結果肯定是每張圖都有不小的差異......至少那個違和感是人可以感覺出來
因此,後續我改用上面提到的 inpaint 策略,就是用一張母圖+inpaint局部重繪去生成剩下的插分圖;中間的細節就是用前面提到的調整 prompt, CFG, denoising strength來實現
其中,母圖的原稿與ai圖是下面這兩張

由右邊的ai圖去生成剩下的表情變化差分圖(inpaint局部重繪)

最後,在用 PS 把右邊因之前手繪簽名生成的手去掉,設置圖片合適的時間軸與每張的播放時間,然後加上新的浮水印就完成了;成品如下:

具體上還是可以感覺得出來一些繪製過程中生成的不一致問題,但重點的表情過渡已經相對自然......至於──如果用PS圖層來做會不會比較快.....如果是全部都電繪肯定是比較快,但要我用修圖的方式去改ai出來的圖,我自己是沒有信心可以改好
畢竟,我、電繪菜雞一枚(:з」∠)
至於為什麼我會來玩ai繪圖作動圖呢.....一來是因為我一個腳報廢在家沒事做,二來就是我本來是在玩 mov2mov 的插件,但效果實在是爛到我受不了,還不如自己一幀一幀慢慢弄 ╮(๑ ◔﹃ ◔๑)╭
最後,在分享一些骰出來的圖好了,玩 Lora真的很有趣;特別是不同風格的 Lora混合起來煉蠱,意外會跑出一些有趣的東西
txt2img

這張我真的不知道怎麼跑出來,p孩感跟整體細節都太神啦!!!!

這張原圖就真的 R18,還好有 inpaint可以慢慢修出泳裝,才能放上來;真是太好了呢(*ゝωб*)b
img2img
原圖是我手繪的這張:

跑圖結果:

這張是我跑出來最喜歡的圖,整個氛圍感超帥;可惜細節的精度不行

這張則是上面用inpaint花了不少時間修細節的圖,細節比上一張好,但氣勢比上一張弱不少,有點可惜
其他還有一些風格不錯,但細節更不行的圖



其實,從ai跑圖的結果,是還滿方便我再回頭觀察我最初的草圖的一些問題,比如衣服摺皺、右手手部不夠明確等等,同時腿以及腳的水花我雖然畫的簡單,但ai在重繪上並沒有做太多的變化,這也說明至少這兩個部份我繪製的結構還算可以
後續應該會把一些自己以前繪製的動圖或草圖都來用ai重製或上色,同時之前拍了不少模型的照片應該也可以用來做ControlNet 的骨架,這樣各種貼貼場景就可以自由的製作了




















































