過年先祝福大家新年快樂...
很久沒想用巴哈,其實我都忘掉以前跟人討論程式碼在哪邊,就來場外分享心得,感覺就是怪怪的。

以前參與過一些開源專案,不過後來玩AI,跟很多人同樣取巧拿Ollama + OpenwebUI 是滿簡單,
但商用化還是難免要嘗試一點新東西,以前PHP的CMS就知道都拿別人的有什麼缺點,
我開始嘗試javascript的AI,主要是他能整合一些前端介面完成一些有趣事情,去年是嘗試Tensorflow.js ,今年是嘗試 Transformer.js,雖然看起來很冷門,但是他有一些優勢。
目前的技術狀況
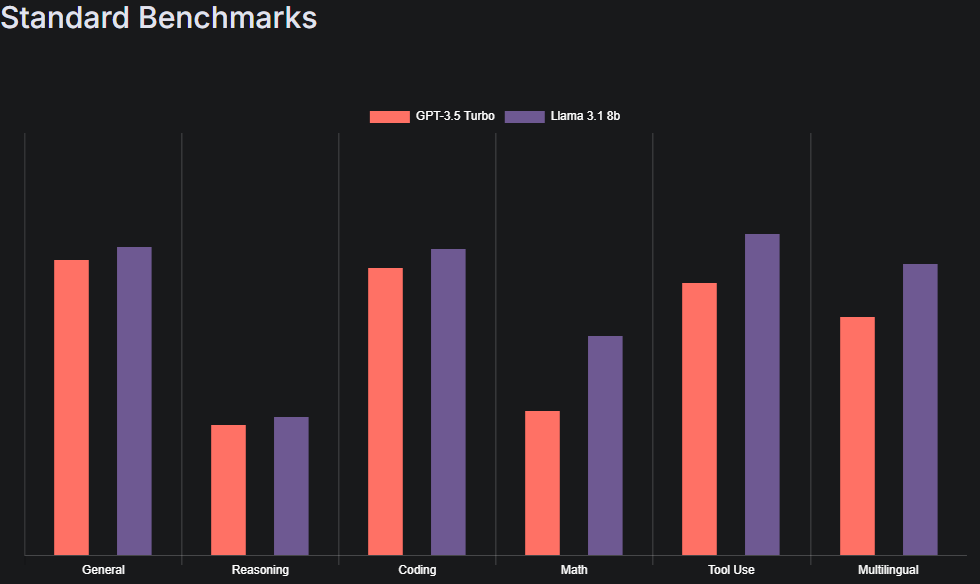
雖然 LLM 的進步速度令人印象深刻,但目前我仍認為它需要至少四五年的時間才能達到超低成本的商業化程度。最近,我嘗試了 Llama 3.1 8b,與 2022 年底的 GPT-3.5 相比有著明顯提高,但相對於末期付費版本的 GPT-3.5 Turbo 卻只有稍微提高了一點,而Llama 3.2 3b大概就是3.1 8b削弱10~15%的表現得的版本,但節省資源是滿多,連CPU直接跑都能比以前GPT 3.5快不少。
Transformer.js 的優勢
我目前正在嘗試使用 Transformer.js,因為它能夠在多種平台上運行(包括 Apple Silicon、INTEL、AMD 和手機顯示晶片),而且不需要安裝或提供伺服器運算成本。這使得它成為一個理想的選擇,讓一般人也能輕易使用。
我這篇主要想要
- 學習新技術
- 通過技術實驗,我希望能夠創造出一些簡單工具,並讓更多的人能夠體驗 AI
我製作的工具是什麼?
簡單說就是讓你在瀏覽器直接跑 AI 模型!我準備了三個模型讓大家玩:
- Deepseek R1
- Llama 3.2
- Phi 3.5
需要什麼配備?
- 瀏覽器:Chrome 或 Edge(抱歉 Firefox 目前不行 )
- 內顯:Apple Silicon、Intel、AMD 都可以!(對不起,獨顯暫時不行)
- 記憶體:內顯 2-4GB 就很夠用了
我製作的應用程式
- 先裝 node.js
- 到這邊下載程式:GitHub Release
- 開啟後選擇模型、按 Open in Browser,然後 Load model 就可以開始用了!
運作介面是這樣,我提供可選模型有三種
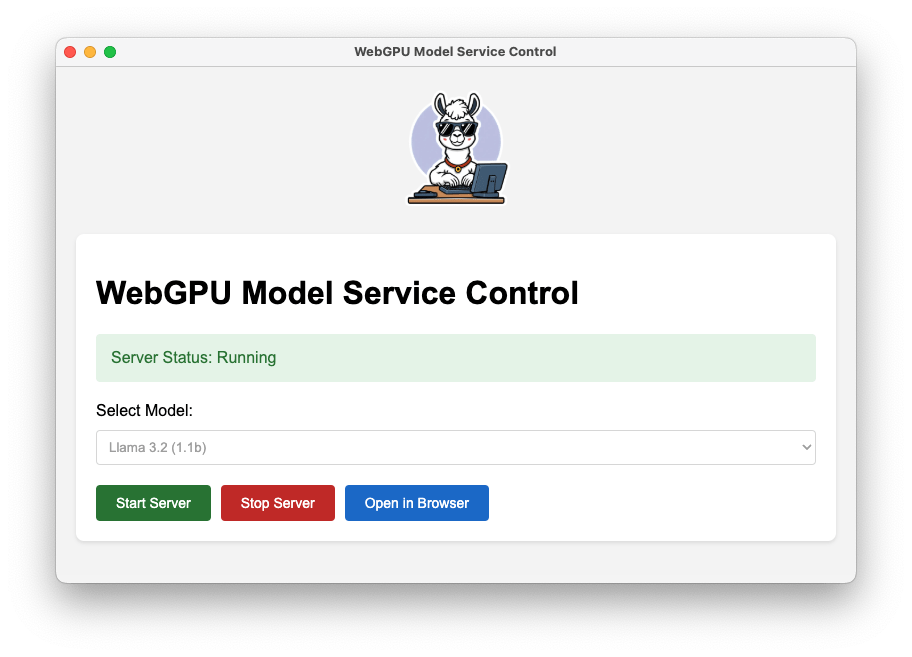
如果你要切換模型,請先 Stop Server
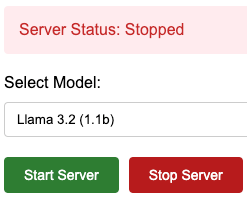
接著選擇其他模型 (ps: 這裡我打錯,其實DeepSeek是1.2b)

重新啟動模型

切換完畢後,會帶入相對應的Logo
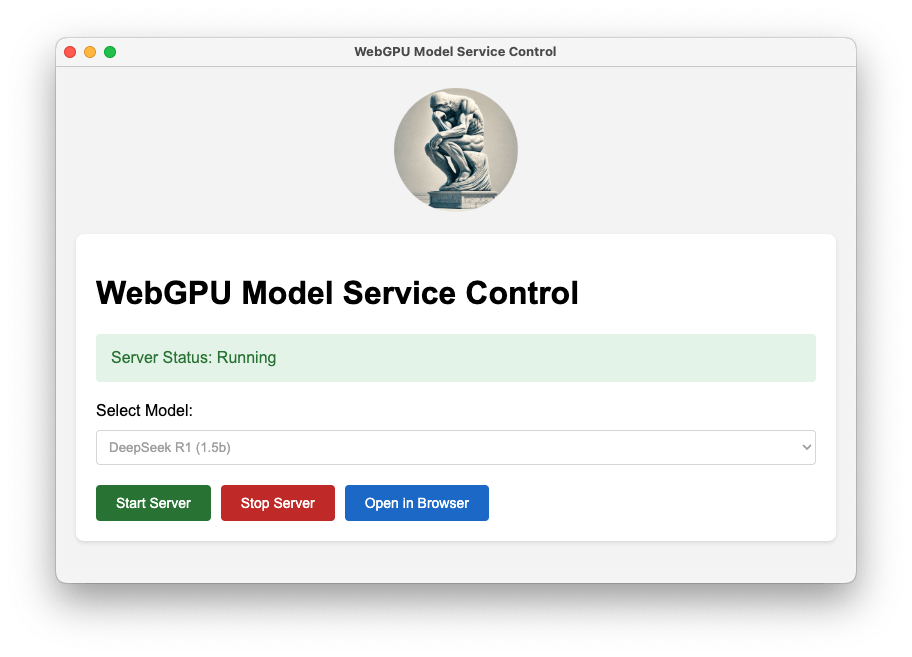
使用時就是點選 Open in Browser
(* 請注意,只支援Chrome,目前只能在內顯跑)

點選 Load model,會進入下載模型,這些模型會暫存於瀏覽器,通常你下次在進來前,他就會自己清掉,不用擔心浪費空間。


我開發是在Mac電腦,也就是Apple silicon M4 上面使用
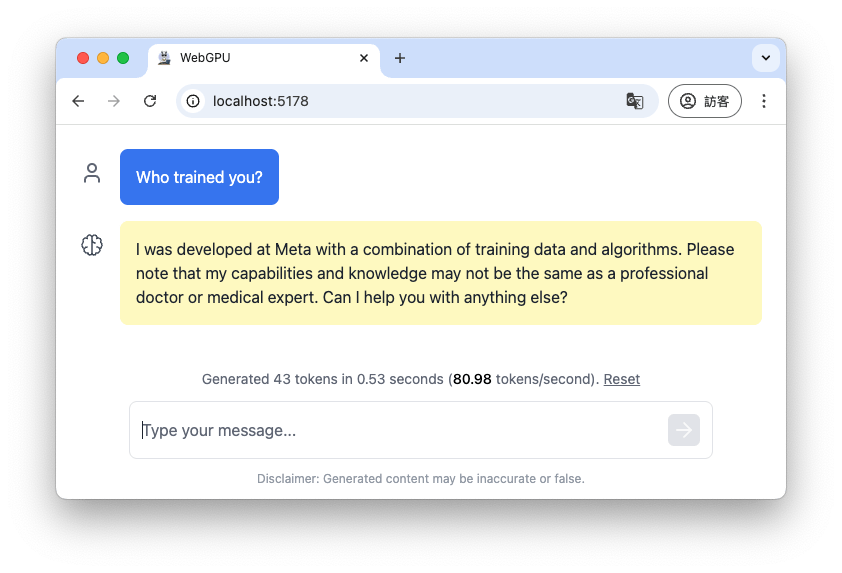
M4跑得還不差,目前故意問 "Who trained you?"
Llama 3.2 1.1b (80 tokens/second)
Deepseek 1.28b (62 tokens/second)

可以看出來,Llama即便是模型小到不行,還是記得自己是Meta建置,但是Deepseek回答就偏向怎麼做的解釋。
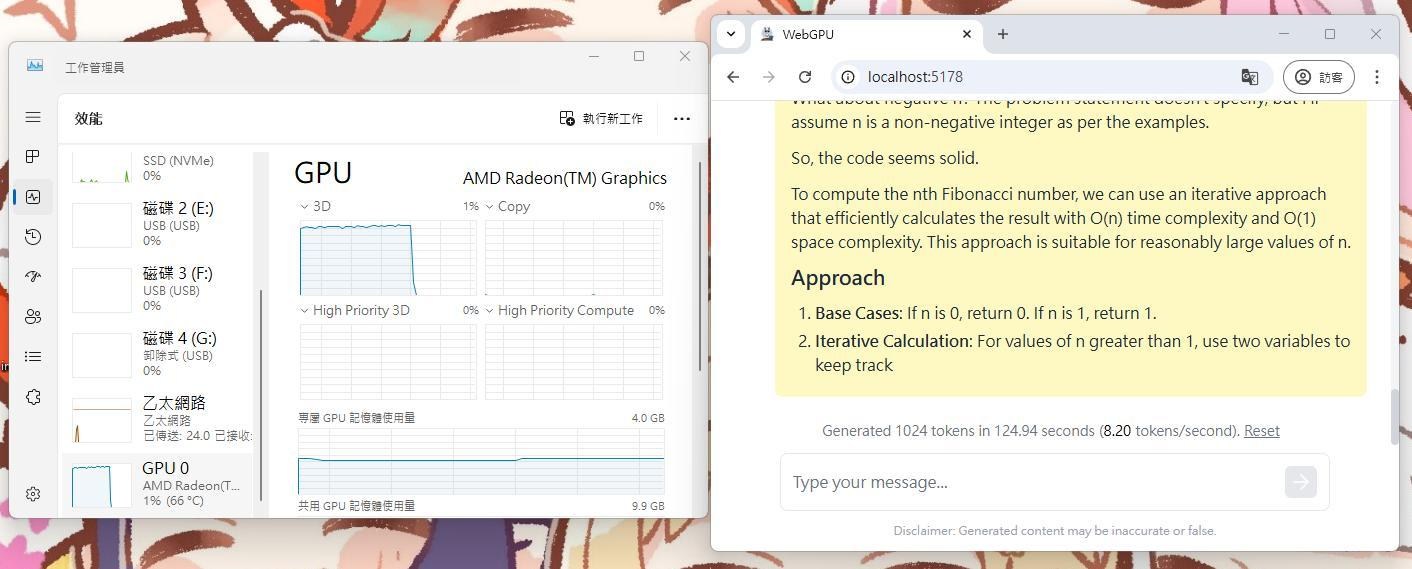
在AMD內顯上面就能發揮顯示晶片效用,這對於AMD是件好事,可惜AMD一點都不在乎的感覺...
Llama 3.2 1.1b (15 tokens/second)
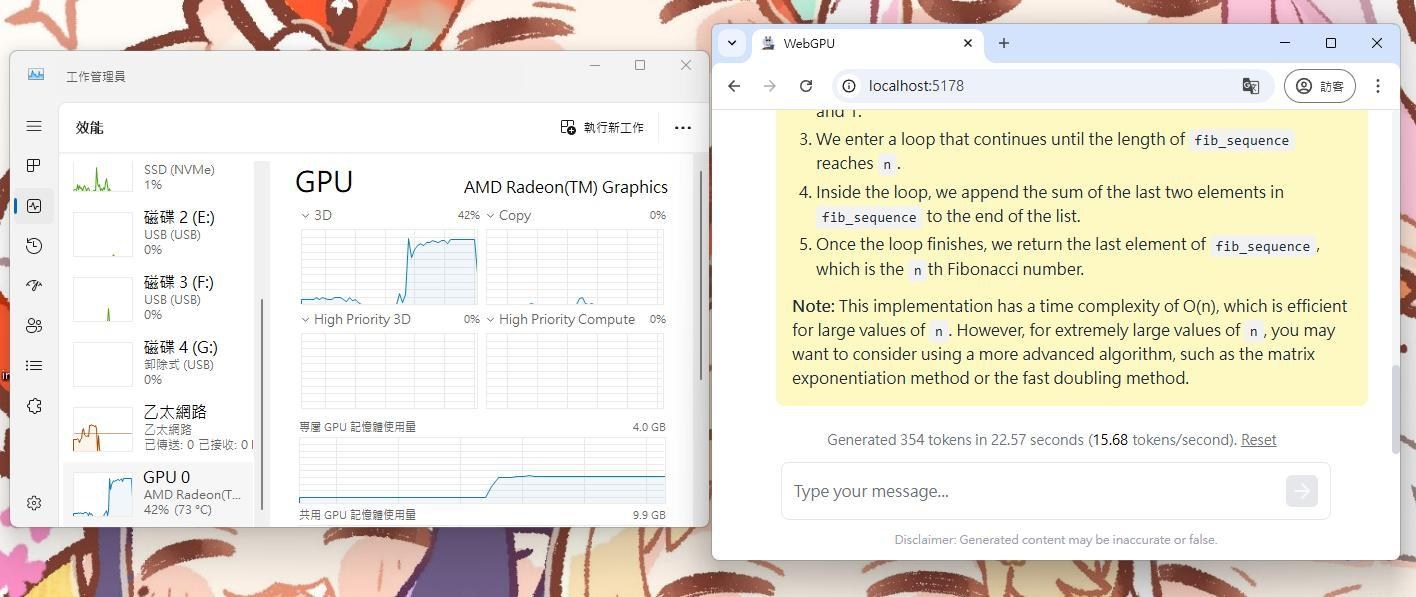
Deepseek 1.28b (8 tokens/second)
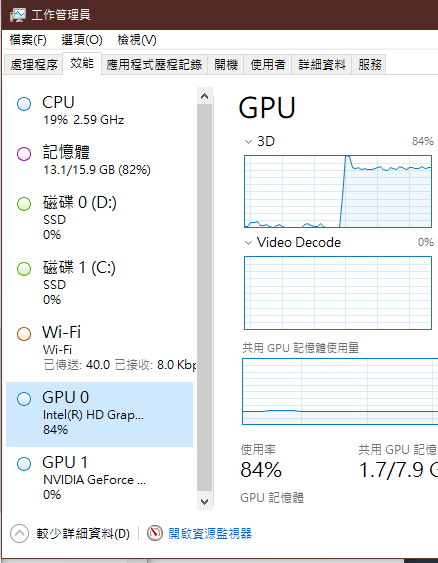
多台電腦嘗試下,Intel在這塊有點弱,但是也是能跑,
另外如果你是筆電,他也是能跑的只是會用內顯去跑...
小提醒
- 目前是英文模型,中文要等大一點的(3b 以上)
- 切換模型前記得先 Stop Server 喔!
- 模型會存在瀏覽器,下次進來會自己清掉,不用擔心占空間
總之,為什麼要用瀏覽器跑?
- 方便!不用搞一堆環境設定
- 跨平台,手機平板都能玩
- 瀏覽器只要還存在,那這端 AI 還蠻有搞頭的
心得?
- 進步速度是很快的:其實llama 3.2 1b,如果你會用英文對話,坦白說比去年底llama 3的7b已經強不少,而且實際上認知並不差,只是多國語言要押到1b應該還要一年,
- 簡單 vs 網路成本:網頁上面跑,商用後的可玩性是真的比較高,畢竟你只要準備好一個網站,剩下都是給遠端跑就行,但缺點就是客戶端loading成本,這段Tansorflow.js也是如此,因為你模型都得放在網路上。
- 實用價值:我有看到一些實驗,例如Next.js 的一些預判行為,或者即時的語音轉文字跟圖形辨識,聲音轉換等等...我認LLM直接跑在瀏覽器應該不需要太久,或許一兩年內或許可以滿足GPT3.5 turbo這個水平用戶的需求。
OS: 好久沒回巴哈寫文章