這是繪圖AI - Stable Diffusion 相關教學與參考資源的額外補充,針對macOS的電腦做stable diffusion補充
因為stable diffusion的模型是基於pytorch製作,而pytorch在2022年底開始支援MPS運算,包含apple silicon晶片(如M1等等)的MPS,所以apple自然也能表現出不錯的速度,當然這發展還很初期,相對於CUDA接近二十年的發展
因此這部分其實ARM晶片性能還未發揮
因此這部分其實ARM晶片性能還未發揮
不過也有突破
若你未來有要開發手機項目,M1的實驗經歷是你非常值得嘗試的項目
1. ARM跑AI本來就不差,但記憶體還沒優化,不過已經有實驗突破,未來會更受重視
光用手機12秒內就可以生成一張Stable Diffusion圖像!Google提出擴散模型推理加速
光用手機12秒內就可以生成一張Stable Diffusion圖像!Google提出擴散模型推理加速
在nvidia已經有不少記憶體優化項目,像是xformers,其實這不歸功於CUDA架構,而是其他開源的研究者 facebook research對其他項目的調整,既然開源,google這研究就是把那套記憶體優化方法放上手機
按照它們說法,能加速30~50%表現,
我在Stable Diffusion 性能測試與加速方法,有對許多顯卡做過測試,
google這個優化,讓手機晶片跑到接近RTX 3060~3070做記憶體優化過的水平
google這個優化,讓手機晶片跑到接近RTX 3060~3070做記憶體優化過的水平
那麼未來如果MacOS上的M1 M2有被注意到,那就一定更快
這意味著你真的要商用算圖,或許是不該猛衝顯卡,而是雇用專業的工程師去研究怎麼使用ARM晶片或者ASIC,然後依據你公司狀況進行變動
去年已經開始有些商家拿Apple mac mini m1做cluster
很有意思
實際上我們軟體工程師用CUDA是為了省事而不完全是要他的速度
說更白就是工程師普遍也是懶得改程式與學新東西
畢竟CUDA有很長歷史,不過性能方面只要願意看一些研究測試數據,應該都會知道傳統顯示卡架構並不是好的選擇,他有先天物理缺陷,而是要用ASIC或整合度高的ARM(cpu、gpu與ram整合性很高),你看微軟與OpenAI都要自研AI晶片,主要就是性價比問題差距非常大,Google從差不多十年前就用得很爽
因此
CUDA算圖非常耗電,通常顯卡超過100w,整台主機會到200w
然而你用macbook air,整個主幾還有螢幕在耗電的情況下,大約就是20-30w上下
如果是公司,多台一點大概跑個幾個月你差價就馬上出現
如果是公司,多台一點大概跑個幾個月你差價就馬上出現
那時候pytorch跟tensorflow都還沒開始支援MPS更不用說現在記憶體優化方法出現
不過Apple拿來跑這個還是浪費錢,我想大多數人還在等ARM開發板的研究,
如果加入後面慢慢改進,ARM這邊還滿有前途的
不過這一切問題回到你知不知道而已,還有有沒有找到最佳發揮的可能
因為我去年已經有朋友投入ARM作為AI邏輯推理的生產,但我當時還有技術障礙並不懂
這非常吃你的知識與技術
因此真正有價值的後端工程師,就能在這時候找出硬體加速運算與穩定這塊
2. NPU還有開發空間
apple silicon的晶片,因為原本就是手機ARM晶片,所以已經有內建NPU,
NPU在跑AI的運算上速度更快更省電,NPU屬於ASIC(特殊訂製晶片),
這類ASIC晶片能在節省記憶體與節省不少電的狀況下,
跑出GPU連續好幾代都追不到的性能,包含即時辨識,
所以很多手機晶片公司都會研發,
而手機的照相這件事情,就非常依賴AI的運作,所以NPU在ARM晶片,發展超過六七年了,
不過跨到電腦應用還是剛開始
因此Apple 2023才開始嘗試提供ml-stable-diffusion,基於NPU運作
因此Apple 2023才開始嘗試提供ml-stable-diffusion,基於NPU運作
按照他們測試,最弱macbook air m1的可以壓到18秒(* 我實際實測更快)跑出一個512*512的圖片,這些都等同大張中階顯卡的運算速度
不過NPU通常只在AI推理運作,ASIC這類晶片中,也只有google TPU提供比較明確的訓練方法,
因此如果你要訓練模型,還是使用google TPU更划算,次之再選GPU,
當然如果你不熟悉XLA/OpenXLA,可以看一些XLA教學以利使用TPU,
也可以繼續用單純用非常耗電又非常貴的GPU....
介面種類如下
- automatice 1111: 使用這方法你至少要是資訊系畢業比較好,這樣指令上你就會容易理解為什麼要那樣做
- ml-stable-diffusion: 這個比automatice 1111更進階應用,屬於更原始的核心程式碼,想開發可以從這邊入手
- Mochi Diffusion: 這適合懂apple電腦的人嘗鮮,可以自訂模型與使用類神經網路,算是最有效發揮apple晶片的產品
- StableBee: 這適合什麼都不懂的人嘗鮮,速度還可以,下載後直接能執行,但不能換模型,單純用MPS
一、 Automatic1111 webUI
這是大家耳熟能響的webUI介面,他的優點是相容性目前最佳的,缺點則是速度最慢,尤其你的pytorch元件若沒裝好,M1 GPU原本算一張圖能有2060的表現,你可能跑出1030還不如水平,後面我會提出建議安裝的步驟,以免你裝錯。
- 請先安裝git,版本任意
- 安裝python 3.10版本,建議3.10.11
- 用git 下載 stable diffusion automatic 1111
在你要放新程式的資料夾中開終端機,建議使用外接硬碟,因為mac寸土寸金
執行git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git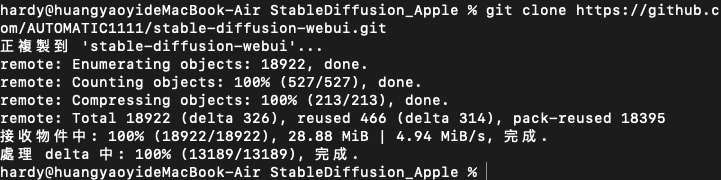
到你的資料夾看,他下載好會新增一個資料夾,同樣方法進去
- 製作虛擬環境放python安裝,主要是mac寸土寸金,不太適合用conda,而是virtualenv比較合適,雖然說conda還是比較穩定
下指令python3.10 -m venv venv
(如果有例外狀況再說,正常都有支援virtualenv)
跑完資料夾內應該有venv
執行 source venv/bin/activate 啟動虛擬環境
- 開始執行stable diffusion第一次安裝
在venv環境下執行安裝,下指令 ./webui.sh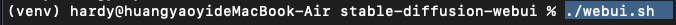
通常第一次會停在一半,主要是還沒有放模型,讓他自己跑第一次主要是便利於自動建立一些資料夾
執行第一次後關掉,下載模型 - 放模型
因為他是直接pytorch跑,所以你可以去下載一般模型
https://civitai.com/
同樣放在model下的stable-diffusion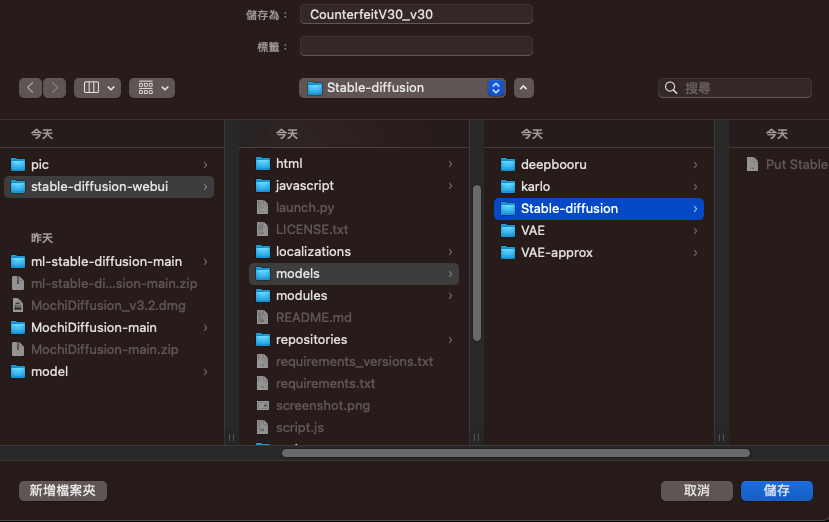
- 再一次執行stable diffusion
同樣指令 ./webui.sh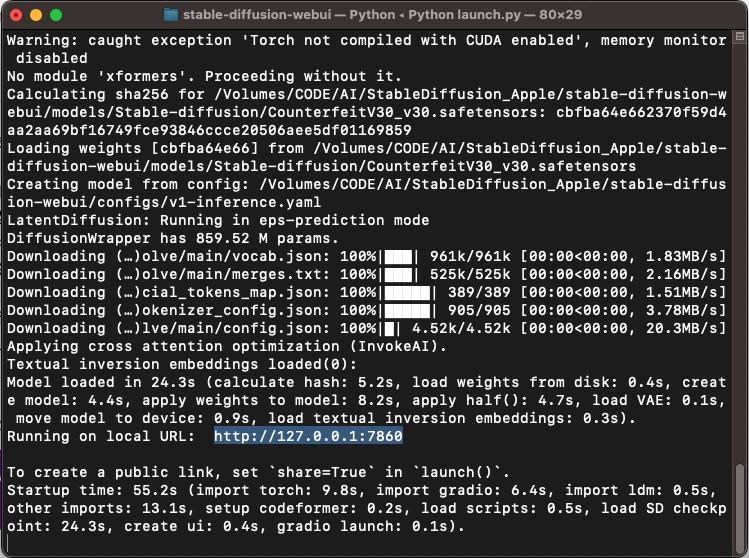
連線一樣 http://127.0.0.1:7860
登入後介面跟一般電腦一樣,你也能做訓練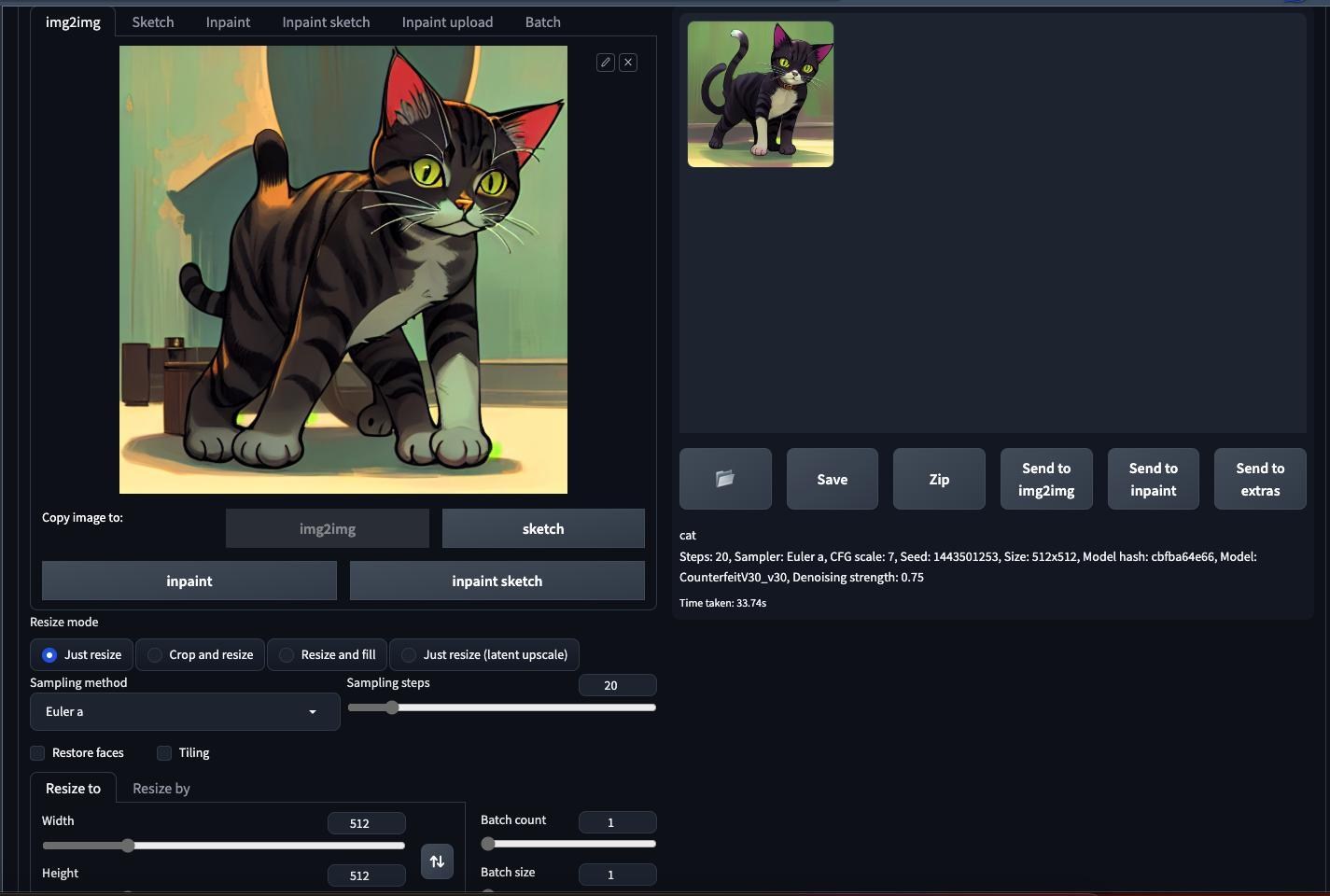
運作後理論上gpu會有效利用
同樣測試一個prompt: cat ,512*512,20 step
txt2img: 30~40秒之間
img2img:25~35秒之間
詳細對比可看Stable Diffusion 性能測試與加速方法
我這台是一台最廉價連風扇都沒有的macbook air M1 8GB版本
但以結果來看
大約性能就是接近1060 6g、2060 6g這類卡,遠遠快於1650或1050超過一分半
如果你N卡xformers沒開,那就是超車3050或1070,xformers是一個記憶體優化策略
目前google才剛通過實驗能讓apple 或高通晶片加速30~50%
所以apple m1的gpu速度,理論上就算stable diffusion能壓到15秒內,至少應該比手機的12秒還快
如前面貼的文章,若真的未來google研究成功導入
那就是能跟3060或3070對頭
我也嘗試跑更複雜的DPM++ 2M Karras,速度也不差,step 25在CFG 10的情況下,大約50秒上下能完成,算是很不錯,至少比一眾顯卡快很多,不需要被風扇噪音與電熱拷問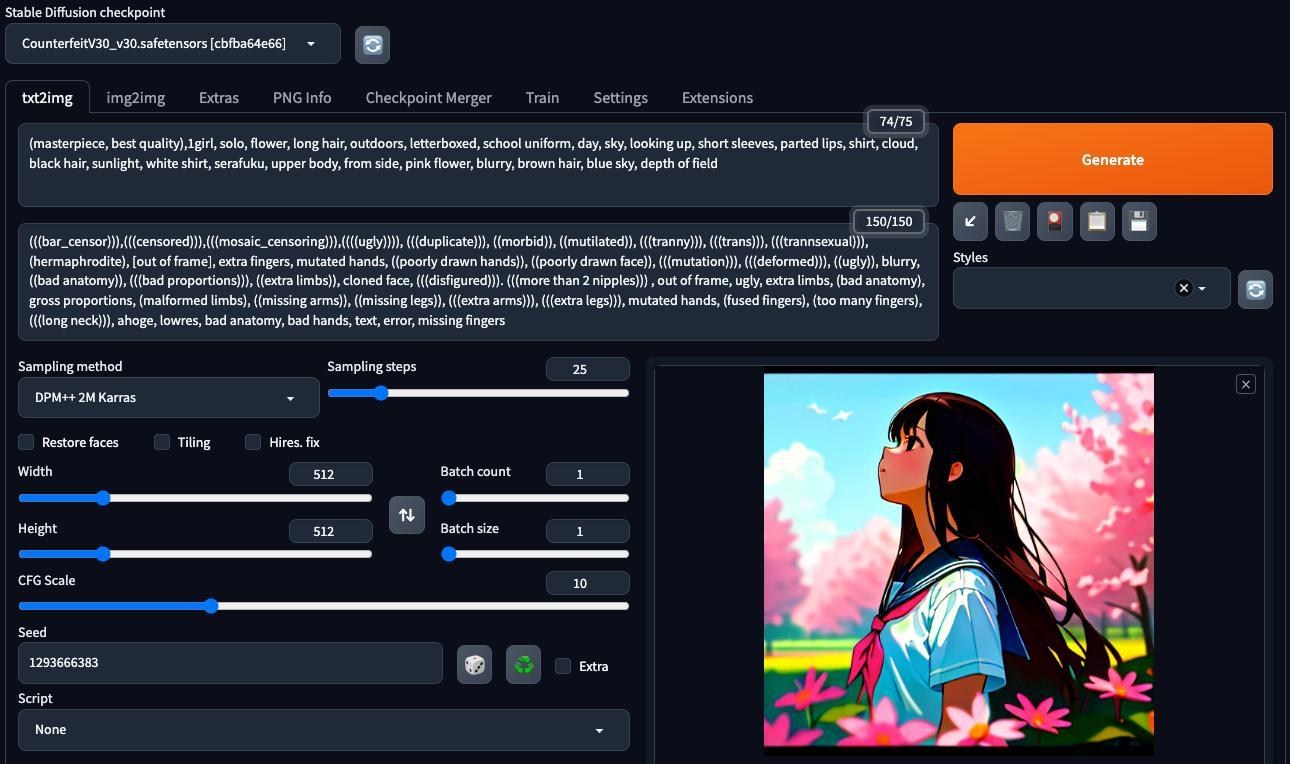

不過因為mac記憶體會跟顯示記憶體搶空間,
所以你在跑圖片時,建議關掉消耗記憶體的東西,
通常大約等於你記憶體扣掉4~6GB才是你目前擁有的顯示記憶體大小,
所以如果你要跑圖,可以考慮買擁有16GB以上的mac mini
當然另一個方法就是不花錢,因爲NPU在算這個非常省資源
未來GPU這邊就等看看google的研究什麼時候能上Pytorch使用
到時候加速大概M1就能降到10秒
開啟額外功能(例如Deepbooru):
macos設定文件是 webui-macos-env.sh
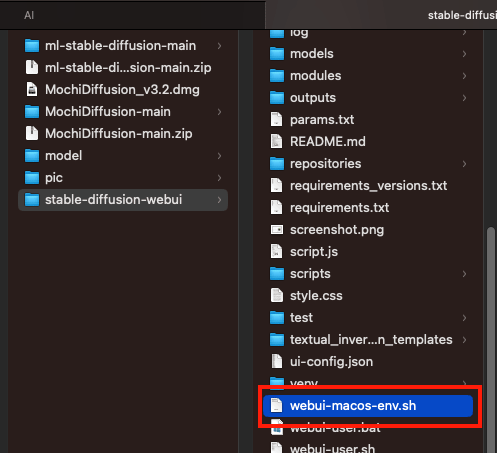
在 COMMANDLINE_ARGS= 這段,後面加上 --deepdanbooru

重新啟動就能執行推演
我測試,除了第一次執行要做下載安裝,後面就是按下馬上得到prompt,算是表現不錯
我測試,除了第一次執行要做下載安裝,後面就是按下馬上得到prompt,算是表現不錯
不過若你有遇到錯誤,建議看我後面寫的例外狀況排除
例外狀況排除:
在macOS底下,大多數pytorch都能正常以MPS運作,只是優化程度多少
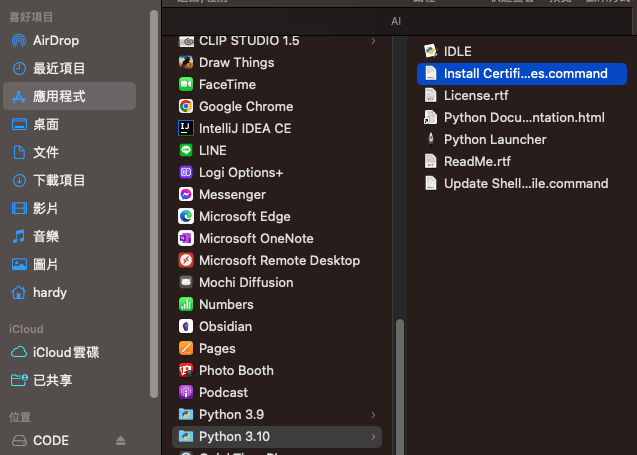
但正常你應該會遇到Python SSL協議的問題,所以有些不運作可以先試試看下面做法
打開finder,進入應用程式,到我們的python版本3.10,執行install
二、Mochi Diffusion
M1這種低階SoC原本是給平板用,他GPU是超低功耗,不過在AI算圖性能上已經接近1060~2060水平
不過更快的NPU是多少呢?
不過更快的NPU是多少呢?
目前測試,大概能拉升到3050~3070之間表現,
都是十幾餘秒之內
主程式你只需要下載下面網址內最新dmg檔案然後直接執行就可以安裝,安裝就是一般mac安裝程式的拖曳方法
第一次啟動跟第一次算圖都會非常久,後面載入記憶體後就沒這問題,反正你如果有用過webUI大概會知道後面就是在跑那些確認與安裝之類的動作,webUI切換模型也是非常花時間
安裝後可以做一些額外設定
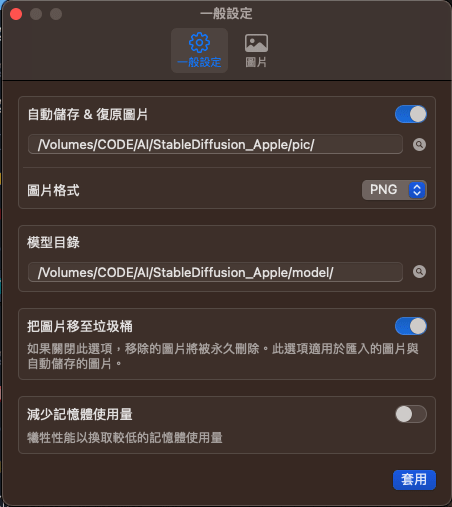
儲存與模型路徑
我個人是把他設成外接硬碟,這樣就可以
雖然不能像automatic1111 那樣全跑在外在硬碟上,但最浪費空間的就能裝在外接硬碟
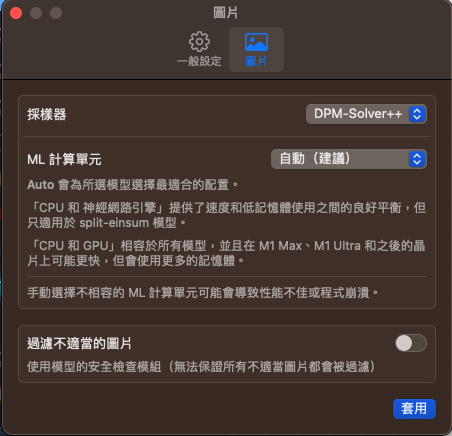
另外更改採樣器可以在這邊用,其中你可以看他介紹,若你要用APPLE NPU(類神經網路引擎),就要下載相對應的模型,也就是split-einsum
(如果你只用就NPU的模型,ML計算單元建議直接選擇類神經網路引擎的選項,載入模型快很多)
這個特殊的 split-einsum model 有兩個下載點
(1) Apple 提供:模型較少
https://huggingface.co/apple
(2) 其他人轉檔的
https://huggingface.co/coreml
另外更改採樣器可以在這邊用,其中你可以看他介紹,若你要用APPLE NPU(類神經網路引擎),就要下載相對應的模型,也就是split-einsum
(如果你只用就NPU的模型,ML計算單元建議直接選擇類神經網路引擎的選項,載入模型快很多)
這個特殊的 split-einsum model 有兩個下載點
(1) Apple 提供:模型較少
https://huggingface.co/apple
(2) 其他人轉檔的
https://huggingface.co/coreml
目前提供83個
點選之後,他模型通常是抓CivitAI去轉成NPU能用的model,所以會附上連結,你能過去看看是否是你要的模型,當然裡面也有一些警告語,

如果是就點選下面圖是路徑下載,進去抓zip檔案
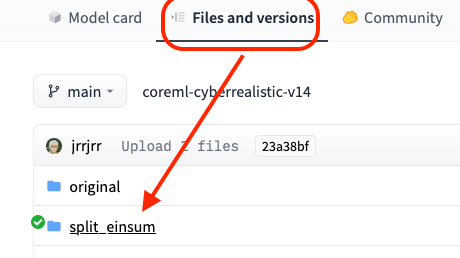
在抓的時候要自己看他資料夾去推測位置,通常是放在split-einsum底下
如果你用錯,他就沒有這麼快
抓完之後,這模型要放在你前面對應設定的位置
然後同檔名為資料夾做解壓縮
進到介面重load就能讀入模型
那麼這個NPU到底優勢是什麼呢?
其實他跟TPU一樣,都是特殊優化的ASIC晶片,主要針對量多的邏輯推理與訓練設計,
像TPU在規模運算就會出現絕對優勢,而APPLE NPU目前測試起來則是針對大照片有一定加速水平,
以我只用M1最低階的air 8gb版本,
5張圖40step就能平均20~30秒內跑出一張 2048 X 2048 的圖,
算是表現不錯
整個介面畫面是這樣,功能還不算齊全,不過展示了NPU的淺力
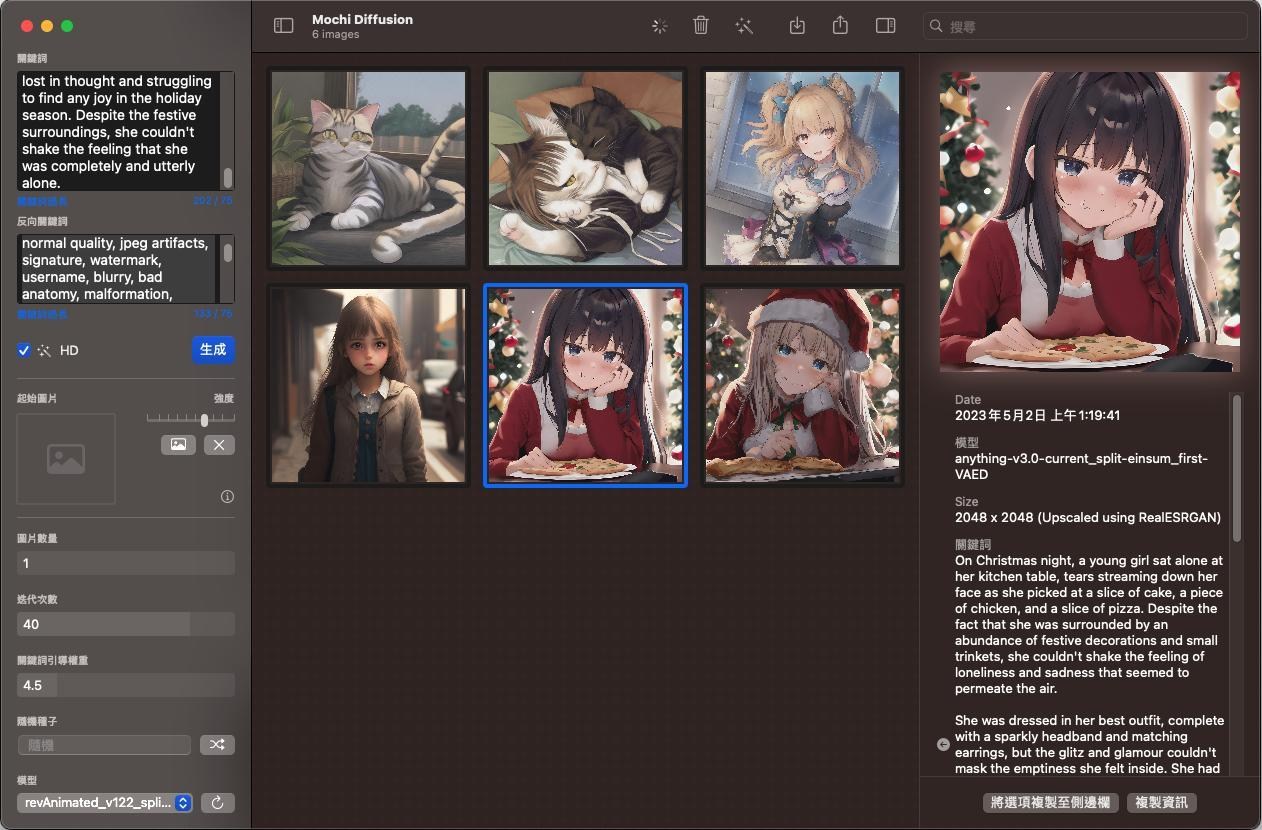
實際紀錄一下速度
整個介面畫面是這樣,功能還不算齊全,不過展示了NPU的淺力
實際紀錄一下速度
大約一張圖在12~16秒之間,看你的CFG設定
大約等於3060顯卡上下的算圖速度
而且溫度,在沒風扇情況下,還在60度以下
電力我想就不用測,我看過有人把m1黑上天說超過50w,
其實正常也知道這種降階就能塞到手機晶片,不可能超過25w,目前大家只能猜,目前我整幾測試,最高就是30w,那顆白豆腐充電器也30w,所以晶片肯定低於25w。

不過這程式是swiftUI
如果你對這項目有興趣還是能用用python
要用apple提供的原版原始碼,那就沒介面
不過可以自己開發一個
如果你對NPU在AI一定比GPU更快這點感到疑問,是可以去看一些影片理解一下他們設計,如前面我所說的,那就一個物理設計上的差異導致的,所以CPU與GPU注定是跑不過NPU這類ASIC晶片
以上是我目前的測試,分享給各位
未來有變化我在慢慢加進來





























