這邊只是做個過程紀錄,懶得排版(包含標點),圖片參考資源可以去本文看
首先是要拿到大量的數據樣本,這次使用python+ADB一直空轉+截圖(掛機)
途中睡覺時不知為何裝置螢幕卡死(可憐筆電跑不動模擬器),截了約1200多張的半灰色21珠,只好刪掉QAQ最終得到了2446張數字樣本之後,試圖用tesseract文字辨識的方式來辨識數字
初期用openCV做了一些前處理包含濾波、轉換色彩空間、二值化、侵蝕+膨脹等等試圖把盾後面的線條去掉
結果還是沒有辦法完全去除雜訊(長的像captcha),而且辨識率也低到炸裂
在調整前整個爛到殼以,也忘記有幾%是對的了(趨近於0)
之後嘗試呼叫tesseract時套用白名單,只辨識數字,估計只有50%有被辨認到,其中只有20%左右正確
也有嘗試過把兩位數拆開來辨識,這樣可以個別縮小白名單範圍,結果辨識率更差了
這樣的效率實在不行,所以就改用相似度比較,在幾種Hash中優先嘗試了dHash(差值雜湊)
dHash的特性是相似的圖片算出來的dHash會相似
運算是先把圖片轉成灰階,縮小成(n*n+1),然後歷遍前(n*n)每個像素(x, y),如果(x, y)>(x, y+1)就把Hash後方補1,否則補0,運算完後可得長度n^2bit的數字
若要比較兩張圖片相似度就要先算出兩圖的dHash,累計同位置相異的bit,最終可得相似度分數(0~n^2),分數越低代表兩圖片越相似(在文章中的demo有做數字反轉成分數越高越像,是為了讓常人感覺比較直覺)
接下來就是要先人工標註16~25珠的樣本圖片作為比較使用,程式在開始時會先把標記樣本算出dHash作為比較標準,然後歷遍每張樣本來分辨出數字然後統計,dhash對於這次的樣本分析非常準確,人工抽查幾十筆完全沒有錯誤,而且各個可能之間的差距懸殊,應該是不可能測錯
接下來就是單純的統計+畫圖表了
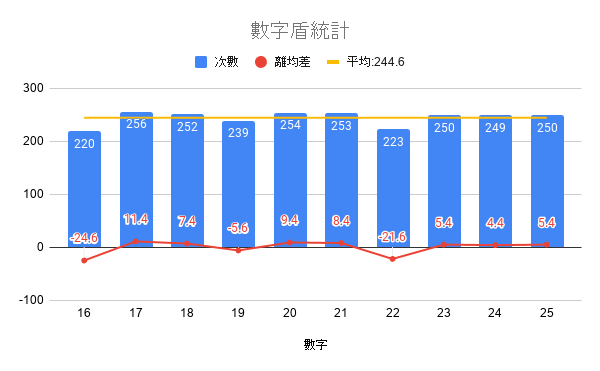
接下來就是單純的統計+畫圖表了
要數字盾截圖樣本的可以來聯絡
程式好像沒必要放github,就直接貼上好了
這是分析的部分程式好像沒必要放github,就直接貼上好了
from PIL import Image
import os
from dhash import dhash_int, get_num_bits_different
def parse_digit(im_hash):
target = None
min_diff = 64
for sam_hash in sample_hash:
diff = get_num_bits_different(im_hash, sam_hash[1])
if diff < min_diff:
min_diff = diff
target = sam_hash[0]
return target
#load marked sample
sample_hash = []
for sam_file in os.listdir('sample'):
sample_hash.append((sam_file.split('.')[0], dhash_int(Image.open(os.path.join('sample', sam_file)))))
i = 1
count = len(os.listdir('imgs'))
res = {}
for file in os.listdir('imgs'):
im = Image.open(os.path.join('imgs', file))
digit = parse_digit(dhash_int(im))
#print(digit)
if not res.get(digit) == None:
res[digit] += 1
else:
res.setdefault(digit, 1)
print('\r%s/%s' % (i, count), end='')
i += 1
print('...done')
for num in range(16, 26):
print('%s:%s' % (num, res[str(num)]))























