前言:
趁著AI熱潮,大家一定學、玩過AI相關的應用,大部分的人知道AI需要「訓練模型」的道理,強一點能知道數個訓練的演算法,跟著網路上的大佬訓練模型、程式碼跑一跑就算是會AI了嗎? 若今天要從零,也就是連資料都要自己收集,更不用說訓練、設計模型的情況下,多少會被多得眼花撩亂的演算法嚇暈吧!
當我們第一個在想「要用什麼演算法?」時,早已陷入一個思考的迷思;AI並不是只是使用什麼演算法就能成功,沒錯,你跑一個算法一定能得到一個「值」,但那個「值」代表什麼? 來自哪個分布? 要怎麼用? 才是製作一個AI真正要思考的。
接續上次期末報告的專題未完成品,花了一兩周的時間重新學習所謂的「AI」,AI不一定得跟巨量資料扯上邊,在少量的資料中找出需要的資訊也是一大門學問。因此在這裡整理了我在學習上遇到的迷思與一些基本演算法。
一樣放個人網站連結>< (最近想修改一下排版)
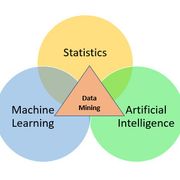
資料探勘、機器學習、深度學習分不清楚?
資料探勘
從巨量資料中撈出需要的資訊,並處理成可理解、可使用的狀態。以往需要使用人工的方式撈,現在借助機器學習,大大減少人工的需求。

機器學習
深度學習屬於機器學習的一環,透過演算法去自動挖掘、預測資料。雖然說是「自動學習」,但演算法本身是固定的,有改動的是其中的參數。

圖源[1]
非監督式學習
不依賴事前的訓練,而直接使用如分群法、聚類法等統計手段進行處理[3]。
範例:
- K-means
- GAN (生成對抗網絡)
監督式學習
透過訓練模型的步驟,自動將參數逐漸去擬合出該資料的分布狀況,偏向於歸納法[4]。 需注意,用來訓練跟測試的資料必須出自於同個分布的資料[5],例如你不能用中文的資料去訓練出英文的翻譯AI。
範例:
- TTS
- 電腦視覺
- 手寫辨識
- Support Vector Machine
如同國小生透過反覆寫抄字本去熟悉各個字的筆劃,監督式學習的AI也是透過大量反覆的練習去熟悉一個資料的分布。
各舉簡單的例子:
K - Means clustering
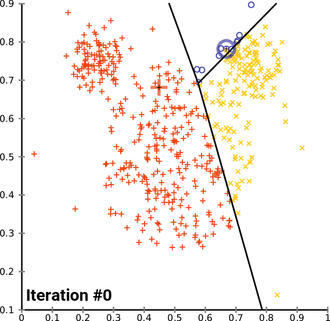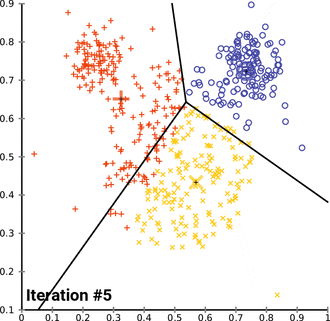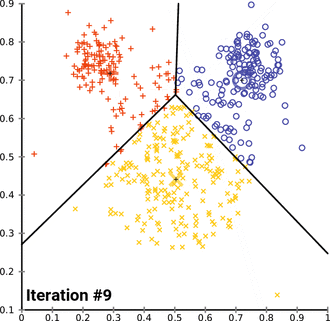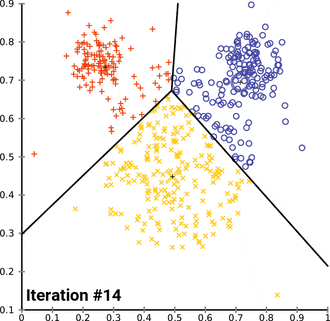 (圖源:wiki)
(圖源:wiki)- 屬於非監督學習。
- 適用於無label的資料。
- 逐漸找出資料的中心點,來得知資料的特徵相似度。
- 找到Elbow point可知道該分類的組數(k)以減少迭代次數。
 (圖源)
(圖源)
Support Vector Machine
 ref
ref ref:wiki
ref:wiki- 屬於監督式學習。
- 基於統計模型。
- 目標在找到能畫分資料的hyperplane(超平面,在n維空間找到n-1維平面),且能使Margin最大化。
看到這裡是否會有疑問,K-means和SVM看起來都是在找到能分割資料的線條/區塊,為何一者是監督式學習,一者是非監督式學習? 討論[6]裡面描述:K-means是分群演算法(clustering algorithm),適用於當我們不知道有哪些群體(class)的時候使用;SVM是分類(classification)演算法,用於決定輸入的資料屬於哪種群(class)。
製作一個簡單的非監督式預測AI模型可以用K-means搭配SVM;K-means找出資料可能的標籤,SVM去擬合資料,並對未來的輸入值做分類預測。
範例:自動摘要生成AI
本學期的研究計畫要製作類似於自動摘要生成的工具,目標在於製作能擷取任意文章中各個主要概念的AI。 在之前的文章中已完成爬文、資料清理、回文消岐的步驟,現在有了稍微整理過的資料,但它們仍然關聯、語意稍弱,為了能將資料去蕪存菁,須研究並計算文本相似度,以做為剔除、融合、關聯....資料的依據。
很幸運的,文獻[7]幫我們整理出目前主流的方法如下。
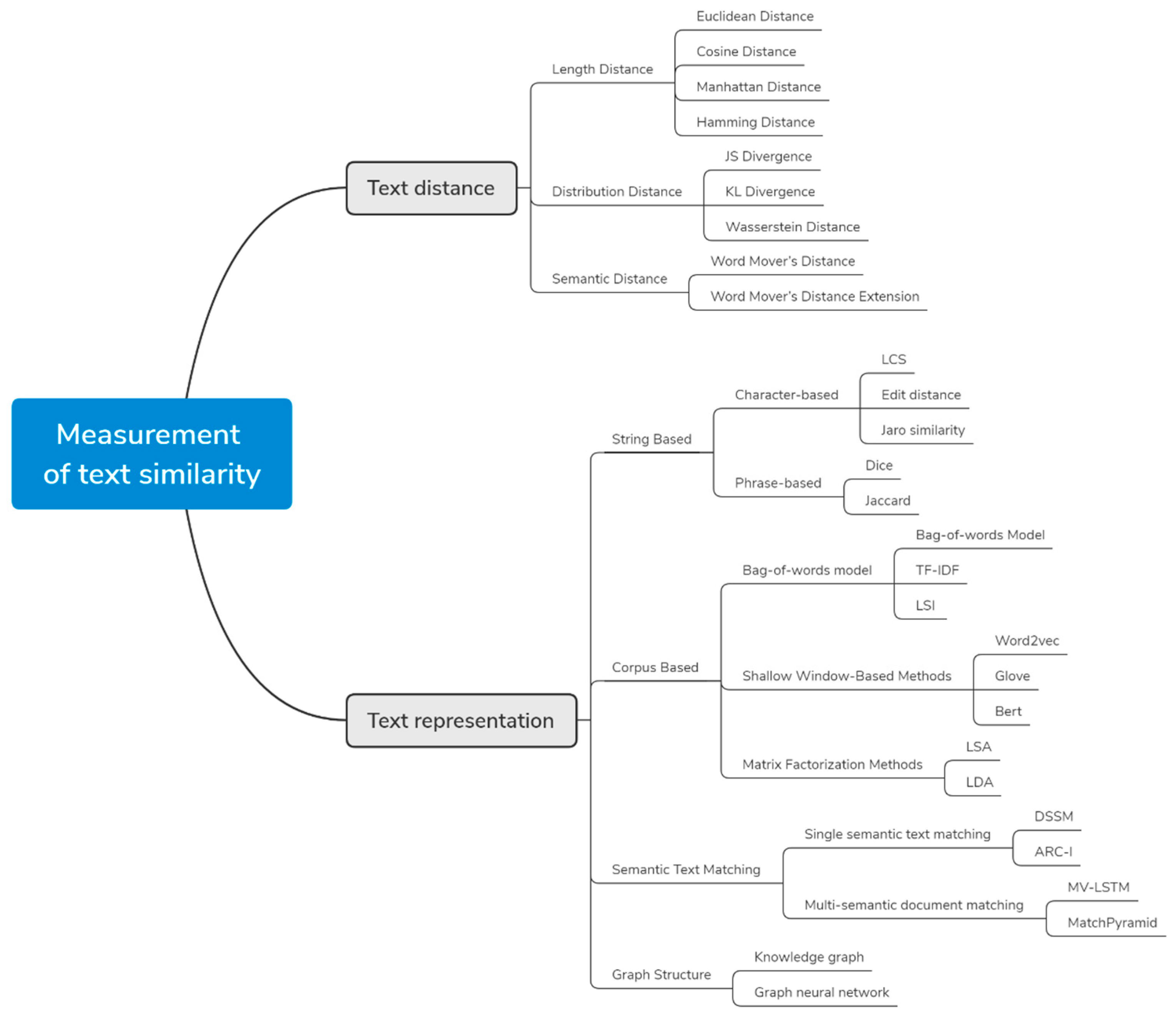 圖源[7]
圖源[7]文字相似度可表示為任兩句話的共通性,其考慮的點有[7]:
- 語意相似度:例如King 跟Queen的概念相近。
- 屬型:例如King有個屬性為man。
目前做自動摘要的主流有分「基於統計」與「基於語意」兩種[7,8]:
- 依照統計法:執行較快。
- 依照語言學:效果可能較好。
文本相似度的計算方法分文字距離法(Text Distance)與詞頻(Text Representation):
- Text Distance:語意上的評估。
- 長度距離
- 歐拉距離
- 餘弦距離
- 曼哈頓距離
- 漢明距離
- 分布距離:好處有(1.)適用於對稱問題,例如Sim(A,B) =Sim(B,A) [7];(2)只用距離計算相似度是不夠的[9]。
- JS Divergence:計算兩分布的相似度,常用於比對某主題與現有主題的相似度。
- KL Divergence
- Wasserstein Distance
- 語意距離:若句子無共用單字,導致距離相似度小,可考慮計算語意相似度。
- word mover’s distance:計算A移動(transform)到B的最小距離。
- 長度距離
- Text Representation:有的相似度計算會使用Knowledge based分類法,例如利用Wikipedia,則不用計算相似度距離。
- string based
- character-based
- Corpus based
- ....
*資料有點多,有些就不細講。
Bag-Of-Word
使用word count去衡量相似度,例如產生文字雲。 較進階的有TF-IDF,多了逆權重去過濾掉出現頻繁但無意義的字。但若句子過短會導致TF不穩定或無意義,且若文本A,B沒有共用的單字,則得出的TF-IDF無意義。[10]
LSA (Latent Semantic Analysis)
將各單詞BOW或TF-IDF的結果以矩陣型式成現,其矩陣大多為稀疏矩陣,可以透過SVD(奇異值分解)去做降維,考慮到SVD的計算量,也是有不做降維的案例。
 Wiki: SVD
Wiki: SVDCorpus based (語料庫)
使用語料庫的好處在於已是基於語言學下的規則,較有意義上的系統,如今大多數詞彙語料庫採用詞性標註(part-of-speech-tagged)[11]。
例如本專題使用Spacy框架,經過pipeline後可得到每個單字的詞性、標籤等資訊。 *詞性、依存關係判斷可以視為分類問題,或使用規則庫。

Glove & Word2Vec是什麼?
上述講到對LSA的co-occurance matrix做SVD是計算量較大的,Glove和Word2Vec克服了這點。
Word2Vec分為CBOW (continuous bag-of-words)與Skip-gram兩種。


後記:
圖源[14],CBOW採用滑動窗口,並使用預先訓練好的模型去預測句子下個單字。
圖源[15],Skip-gram則是給一單字,然後預測與該單字最相關的上下文。
Glove是基於全域詞頻統計的工具,結合LSA與Word2Vec的優勢。[16]
- LSA(Latent Semantic Analysis)可以基於co-occurance matrix構建詞向量,實質上是基於全域語料採用SVD進行矩陣分解,然而SVD計算複雜度高
- Glove沒有直接利用共現矩陣,而是通過ratio的特性,將詞向量和ratio聯繫起來,建立損失函數,採用Adagrad對最小平方損失進行優化(可看作是對LSA一種優化的高效矩陣分解演算法)
*心得:Glove、Word2Vec、LSA都是做詞Embedding的工具,撇除算法不同,主要差別在於基於及時統計或倚賴pre-trained資料集。
題外話:BERT
LSA和Glove有個缺點是,由於共現矩陣並沒有考慮到上下文的關係,導致每個單詞的Embedding都是一樣的,而由Google推出的自注意(self-attention)框架改善了這點。[17]
簡單說Self-Attention套用了滑動視窗的概念,每次考慮句子中的一部分,並加上位置的權重,去篩選出一個句子中的重點在哪裡,也因如此,相同單字在每個句子中的重要程度也會不同。
圖源[ref],Encode負責將輸入轉成可處理的向量資訊,Decoder負責將資訊轉成結果輸出。
在BERT (Bidirectional Encoder Representations form Transformers) 模型中大量運用了Transformer(也就是self-attention)的觀念,具體我也不是很熟,推薦看:自然語言處理中的Transformer和BERT - 知乎 (zhihu.com)。
但BERT計算量大,不常用在文本相似度計算[7]。
講到BERT有點離題了,我們的目標在於如何設計一個處理過程,能剔除掉與文本主題較不相關的資訊。參考[8]的作法,使用了以下技術:
- LSA:以統計方式求出該句子中的單詞的共現因子。
- TFSF:該論文自創,類似於TF-IDF的概念,差別在於用句子間的詞頻,而非文本間的詞頻。
- n-gram:由於該論文處理的是中文,使用n-gram找出最有可能的斷句。
- Jaccard:求LSA矩陣中各句子間的關聯性。
- 模糊理論:讓句子間能有關係的推導。
最後篩選出通過閥值的句子作為該文章的摘要句。
後記:
之後可能參考[8]的做法,改良專題作品。 最近在拚研究所推甄的資料,專題大概來不及實做完。 好多東西要捨取,好怕。文獻*因為這篇是網路文章,所以文獻也找得比較鬆散、多半來自網路的。 實際的正式論文已經看了40多篇,快吐了o( ̄┰ ̄*)ゞ
好多東西要捨取,好怕。文獻*因為這篇是網路文章,所以文獻也找得比較鬆散、多半來自網路的。 實際的正式論文已經看了40多篇,快吐了o( ̄┰ ̄*)ゞ
- Difference in Data Mining Vs Machine Learning Vs Artificial Intelligence (softwaretestinghelp.com)
- Deep Learning vs. Machine Learning – What’s The Difference? (levity.ai)
- 無監督學習 - 維基百科,自由的百科全書 (wikipedia.org)
- 監督學習 - 維基百科,自由的百科全書 (wikipedia.org)
- 【機器學習2021】預測本頻道觀看人數 (上) - 機器學習基本概念簡介 - YouTube 李宏毅老師系列課程
- (2) Can any one tell me what is the difference between k-means classification and svm classification? - Quora
- Wang J, Dong Y. Measurement of Text Similarity: A Survey. Information. 2020; 11(9):421. https://doi.org/10.3390/info11090421
- 周智勳, & 丁泓丞. (7 C.E., May 20). 增強型潛在語意分析基礎之文件自動摘要. Http://Chur.Chu.Edu.Tw/Bitstream/987654321/42894/1/098CHPI5392027-001.Pdf. http://chur.chu.edu.tw/handle/987654321/42894
- Deza, M. M., & Deza, E. (2009). Encyclopedia of distances. In Encyclopedia of distances (pp. 1-583). Springer, Berlin, Heidelberg.
- Croft, D., Coupland, S., Shell, J., & Brown, S. (2013, September). A fast and efficient semantic short text similarity metric. In 2013 13th UK workshop on computational intelligence (UKCI) (pp. 221-227). IEEE.
- 語料庫語言學 - 維基百科,自由的百科全書 (wikipedia.org)
- 斯坦福大学的词向量工具:GloVe – 标点符 (biaodianfu.com)
- (十五)通俗易懂理解——Glove演算法原理 - 知乎 (zhihu.com)
- Continuous Bag of Words (CBOW) - Single Word Model - How It Works - ThinkInfi
- Skip-Gram: NLP context words prediction algorithm | by Sanket Doshi | Towards Data Science
- 史上最全詞向量講解(LSA/word2vec/Glove/FastText/ELMo/BERT) - 知乎 (zhihu.com)
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.