申論題:
Q. SVM
A. 透過決策邊界將資料作最大化的二元分類。
Q. KNN
A. 找出距離待標記點最近的k個已標記點,推測待標記點的正確分類。
Q. K-MEANS
A. 把n個點透過歐式距離劃分到k個群中最近的中心點。
Q. RNN
A. 將多層神經網路中各層隱藏層的輸出直接追加為該層本身輸入的自迴路。藉此構造使得可以記憶該層之前的輸入,當輸入資料為較長的時間序列時,神經網能思考在當前觀察的資料與之前觀察的資料間彼此的關係。
Q. LSTM
A. 相較於RNN,LSTM藉由遺忘門、輸入門及輸出門的概念,使得神經網路可以避免在BP學習過程中所引發的梯度消失問題,所以相較於RNN,LSTM可以長時間安定轉移內部狀態向量。
Q. GRU
A. 與LSTM相同,但將門的數量簡化為更新門與重置門,使得GRU具備更有效率的記憶機制。
Q. SOFTMAX
A.
Q. SIGMOID/TANH/RELU
A.
![]()
Q. LINEAR REGRESSION
A. 利用一個或多個自變數(特徵)去描述一個因變數(目標)
Q. Supervised Learning
A. 從給定的訓練資料中學習中一個函數,當新的數據到來時,可以根據這個函數預測結果。監督式學習要求訓練資料需具有特徵輸入和已標註輸出。代表有CNN(分類)、BPNN(回歸)。
Q. Unsupervised Learning
A. 不同於監督式學習,非監督式學習的訓練資料的輸出沒有被標註,讓模型自行找出與輸入資料相應的結構(聚類, Clustering)。代表有K-means。
Q. Semi-Supervised Learning
A. 介於監督式學習與非監督式學習間,訓練資料包含已標註輸出和未標註輸出。代表有GAN。
Q. Reinforcement learning
A. 只給予神經網路輸入資料,若神經網路對輸入資料作出正確的輸出則給予正評價,使得神經網路以取得最大評價作為目標來調整參數。代表有Q-learning。
Q. Vanishing/Exploding gradient problem
A. 若神經網路的活化函數微分後最大值小於1,則在進行BP學習時會因鏈鎖律關係導致離輸出層越遠的網路越不會被訓練到;反之若微分後的值大於1,則離輸出層越遠的網路,會因鏈鎖律關係導致調整過大而導致網路發散。
Q. Overfitting/Underfitting
A. 過擬合是指神經網路訓練時由於完全適應於該學習資料。導致該神經網路無法適用於訓練資料以外的樣本。相反的。欠擬合通常是因為訓練樣本或者輸入資料不夠,導致神經網路整體表現過差。
Q. Gradient-based learning methods
A. 函數值減少最多的方向
Q. PCA
A. 將原先資料集透過降維方式轉化為較小資料集的一種資料壓縮方法。
Q17. 請描述影像偵測與影像辨識差異?
Q18. 請問分群與分類的差異?
分類(Classification):根據已被標記的資料建立模型,使得可以預測未標記資料的類別。
分群(Clustering):未標記資料會朝向最近的群中心靠攏,會根據資料分布情形不斷調整群中心位置。
Q19. 何謂人工智慧、機器學習、深度學習?
人工智慧:電腦可以在接收到資料時,根據程式語言編寫演算方法或資料庫作出相應反映。
機器學習:電腦根據輸入資料以及演算方法進行自我訓練與學習。
深度學習:基於多層次人工神經網路(隱藏層層數>1)的一種演算方法。
Q20. CNN
計算題:
Q. 卷積運算/最大池化法/平均池化
參考資料:
 創作內容
創作內容
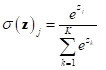





 C# (1)
C# (1)