ch5
屬性分兩種:
synthesized attribute 合成(綜合)屬性:屬性來自於下面的小孩child、兒子孫子,
常用在計算,a=b+c,a是來自下面b+c算出來的結果。
inherited 繼承屬性:屬性來自於左子樹(哥哥)、或父親parents,
常用在宣告int a,b,c。
ch6 靜態檢查和型態
靜態資料型態檢查(編譯時(compile time)檢查):大部分程式語言為此類
動態(執行時(runtime)才檢查):只有Lisp、Prolog(皆為人工智慧語言)
靜態檢查:
型態、控制流(C裡面break的用法)、唯一性、名稱相關的檢查
多載(overloading) 同name,依靠型別來決定
強制型別轉換(Coercion)
多型(Polymorphism) 繼承相關
one-pass:程式碼掃一遍便可檢查完型態(C、pascal、Fortran)
multi-pass:掃多次檢查(Java、C#)
Type Expressions:
Tree forms
Directed Acyclic Graph(DAGs)
Cyclic graph
ch7 執行時環境
procedure:argument引數丟給procedure算完 結果從argument傳回 (考慮call by value,reference)
function:會return值
A->B->A recursive
A->A->A self-recursive
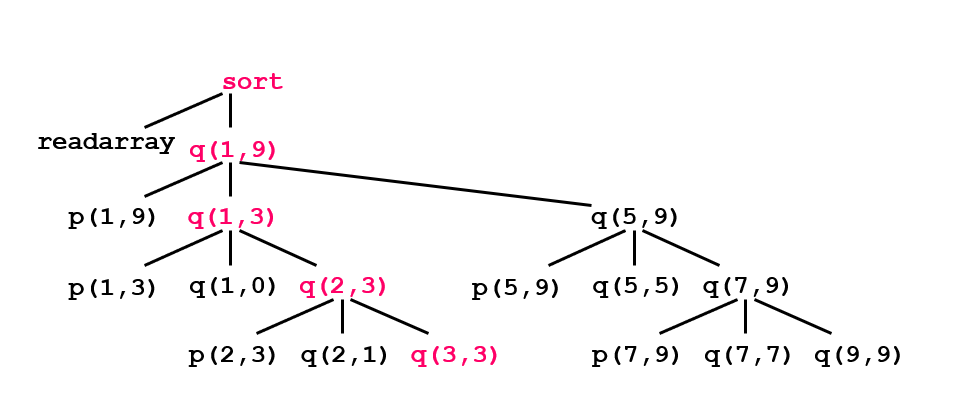
Activation Trees(圖) 程式碼為上方的圖(做quicksort、partition等運算)
程式從read array開始執行,完畢後離開 進入q(1.9),再進入p(1,9) 離開p(1,9)來到q(1,3)
再進入p(1,3),完畢離開p(1,3)來到q(1,0),完畢離開q(1,0)進入q(2,3),再進入p(2,3),完畢再離開p(2,3)來到p(2,1)完畢再離開p(2,1)再進入q(3,3)
在執行到這一段時,紅色那條線的資料全部都要在 activation record(要在stack裡)
activation record:活動紀錄動作為堆疊的配置,與呼叫順序有關(執行時才決定)
scope 範疇:變數參考哪邊的變數,名稱與物件做binding繫結
environmnet 環境:宣告的變數名稱與記憶體位置或屬性作繫結的過程
動態繫結:當有被呼叫到時才被啟動(Activation record)、生命週期與名稱綁定,runtime時才決定
靜態繫結:對一個副程式做宣告,宣告名稱變數名稱變數範疇等,例如constant
caller 呼叫者(在範例中指主程式):主程式呼叫副程式,傳argument引數進入副程式,設定control link,access link,並把目前機器狀態存起來(PCB PSW)
callee 副程式:副程式被呼叫之後會設定local data,設初始值,算完後return value傳回主程式,主程式便把副程式相關的activation record刪除
Activation Record包含:
frame point(fp 底),產生新的後會指向sp
segment point(sp 頂),產生新的後等fp指向後再往下移
control link指向 原先fp的位置
1. return value,actual
2. parameters(實際參數)=argument,主程式呼叫副程式時要先把值放入這 才呼叫副程式
#(formal parameter = parameter)
主程式 ---(傳給)--> 副程式:argument引數
副程式(接收、傳入的值):parameter參數
3. control link 呼叫順序(dynamic動態)等到呼叫才產生呼叫的sequence,指向前面的呼叫自己的activation record的fp
4. access link(static靜態)在compile time已確定,指向上一層的用到的名稱或變數
5. save machine status
(以上為主程式caller負責)
----------------------------
(以下為副程式callee負責)
6. local data
7. temporaries
在這張圖中原本只有藍色的caller,橘圈的fp指向記憶體的底端,橘圈的sp指向頂部,
等到呼叫副程式 Stack往下增長後 fp移動到粗體的位置(橘圈sp的位置),而sp移動到stack頂部,Control Link則指向原橘圈sp的位置
而如今程式碼是這樣
s:sort
q:quicksort
p:partition
e:exchange
依照前面紅色線的樹狀圖
主程式sort (藍字 從倒數四五行開始begin) 執行到q(1,9)時
q(1,9)執行q(1,3)
q(1,3)執行時進入到了p(1,3) #經 i:=partition(m,n)這行進入p function
p(1,3)再進入e(1,3) #經begin ... exchange(i.j)這行進入e function
此時狀態如下圖
最右邊的圖 黑色粗線為Control Link,也就是function呼叫的順序,藉以讓被呼叫的function執行完畢後知道要回到哪裡 來繼續程式的執行。
而綠線為Access Link,是這個區塊中可視的變數或物件,紀錄這個變數名稱指向哪個位置。
換句話說是區域變數的概念,如果找不到區域變數則往上面一個層級找。
如果變數在p(1,3)中找不到 會先隨著綠線進q(1,3)找,q(1,3)也找不到,便再隨著綠線到s裡面找#因為p function 被定義再q function中 (p被q包住了,q被s包住了)
call by value:數值傳進來,argument不會受到影響,引數不會受到計算改變
call by reference(address):傳的是變數的位置,內容改的話argument會受影響
copy restore:少用
call by name:少用
ch8 中間碼產生
1. 適應要轉的目的地的碼
2. 機器無關的目的碼最佳化(中間碼做最佳化)
中間碼表示方法
1. Graphical representations圖形化表示(e.g. AST抽象文法樹)
Production Semantic Rule
S ® id := ES.nptr := mknode(‘:=’, mkleaf(id, id.entry), E.nptr)
E ® E1 + E2E.nptr := mknode(‘+’, E1.nptr, E2.nptr)
E ® E1 * E2E.nptr := mknode(‘*’, E1.nptr, E2.nptr)
E ® - E1E.nptr := mknode(‘uminus’, E1.nptr)
E ® ( E1 )E.nptr := E1.nptr
E ® id E.nptr := mkleaf(id,id.entry)
AST:
優點:容易重構(最佳化時)
缺點:耗記憶體
DAG(Directed Acyclic Graph 有方向性 無cicle的圖):AST的變形
edge:無方向性
arc:有方向性
2. Postfix notation(後置式) (Java用的bytecode),容易產生,堆疊操作不易最佳化
a :=((b * (-c)) + (b * (-c))) 轉為 a b c uminus* b c uminus * + assign
3. Three-address code 三位址碼 (quads四項碼 quadruple code) 當今最常用的方式
三個運算元,一個運算子(操作),先看運算子有幾個 就有幾道三位址碼
優點:全域性的最佳化容易重排
缺點:會用到很多暫時變數 t1,t2,t3...
x := yop z
搭配文法樹產生三位址碼,
左邊的樹(base on AST) 可以化簡成右邊的表示方法(base on DAG)
4. Two-address code 兩位址碼 (triples三項碼)
三位址碼的不儲存結果(result)方法,#label號碼為結果存放空間
優點:不需要用到暫時變數(被隱藏起來了)節省一些空間
缺點:不容易做最佳化(最佳化交換時 內容會跟著變動)
x := op y is the same as x:= xop y
5. Indirect Triples (間接三項碼)
三項碼再加一個label的mapping table(對照表)
優化時僅指標變動
優點:暫時變數可以被隱藏起來,目的碼也容易被優化
缺點:需要額外的資料結構和空間
![]()
A :array [10..20] of integer; #10,11,12,13,14,15,16,17,18,19,共10個元素
… := A[i] = baseA + (i - low) * w
= i * w(4) + c
wherec = baseA -low * w
withlow = 10;w = 4
二維元素,先決定是row-major 還是col-major
A :array [1..2,1..3] of integer;
A :array [1..2, 1..3]of integer; (Row-major)
n2=up2-low2+1 =3-1+1=3 col
… := A[i,j]
= baseA+ ((i1- low1) * n2 + i2 - low2) * w
= ((i1 =i×n2=3) + i2=j) * w + c
wherec = baseA - ((low1 * n2) + low2) * w
withlow1 = 1; low2 = 1;n2 = 3;w = 4
ch9 跟機器相關的目的碼產生
部分(local)最佳化 (全域最佳化不太可能,為np-hard問題)
目的代碼:
1. Absolute machine code(execuable code)絕對機器碼 (例如SIC),目的碼含要執行的記憶體位置,一定要丟到那個位址才能跑
2. Relocatable machine code(object files for linker) (組譯產生出.obj,不能直接執行,執行前要透過link(ref、參考連結等,解決重定位問題)轉成.exe)
3. Assembly language,執行前還須經過組譯
4. Byte code forms for interpreters(堆疊操作碼,需要虛擬機 e.g.JVM)
假設今有一台機器使用2位址碼(3項碼),1word=4bytes
記憶體定址模式:
1. Absolute(Direct):絕對定址法(直接) 會用到記憶體(1次)
2. Register:只用暫存器,不會用到記憶體(0次)
3. Indexed:索引,拿暫存器的內容與常數相加 當成要去的記憶體位址(1次)
4. Indirect register:間接暫存器,把暫存器的內容拿出來當記憶體位址(1次)
5. Indirect indexed:間接索引定址,把暫存器內容跟常數相加 當成要去的記憶體位址,再拿這個的內容當記憶體位址去,會有兩次記憶體參考(2次)
6. Literal:立即值(0次)
計算cost (Definethe cost of instruction):1 + cost(source mode) + cost(destination mode)
#所有指令都有1個1的cost
用來計算的範例↑
區域優化,透過這些方式來進行優化
Evaluation Order
Rearrangement of quadruples for code optimization
 創作內容
創作內容
 休閒日誌 (0)
休閒日誌 (0)