之前在亂逛生成式「AI」相關消息的時候剛好看到這一篇專訪
看完他對生成式「AI」對於對抗中共極權的意見時,我感到懷疑:「是在開玩笑?」
尤其是這句話
「但現在網友只要想辦法把我剛剛提到的這個語言模型,通過一個隨身碟的大小拿到手上,之後就不再需要網路連線。也可以一直去問它『當年的幾月幾日究竟發生了什麼事情?』」
先不提身在極權國家,網路被限制的人民到底能不能入手他所謂的「模型」,在他理想中誰都能對它訓練的開源模型,真的有他想像中的那麼可靠?(更別提還有部分訓練資料源於盜版網站這種事情)
讓我來問個問題,你覺得孔雀的雛鳥長怎樣?
牠是長這樣子呢?
![]()
還是長這樣?
答案是上面的,你仔細看就會發現下面的「雛鳥」有跟樹枝一樣錯綜複雜的腳
也許你會想說「這不過就只是一種案例嘛」
但是呢......
![]()
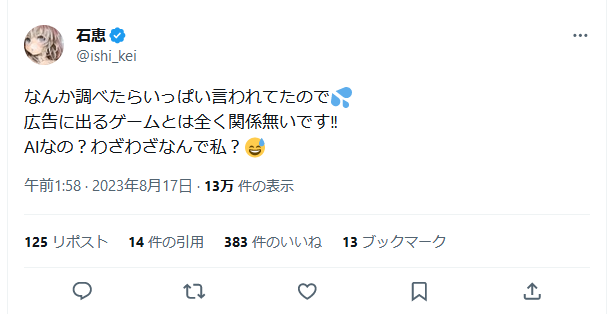
糞GAME發行商在廣告中使用以石惠老師的圖做針對性訓練(LoRA)產生的模型,造成當事繪師困擾
以及戰爭、暴動時常常出現的以假亂真圖片消息......
當然,這些都是圖片類的案例,不過要用文字來舉例的話......
生成式 AI 反而可以在造成混亂上這點佔據極大的優勢
一旦產生了「沒有任何消息來源是可信任的」的風氣,或是正確消息被大量垃圾淹沒,就算在這混亂中想要矯正視聽(如指證孔雀雛鳥的那個推友),也會遇到各種阻礙。
啊在這團混亂中你覺得是攻擊方贏了還是防禦方?
如果真的想要預防中共的言論審查,與其跟隨Sam Altman
(那個想要拿加密貨幣換你虹膜資料的)、楊立昆之流去造出一個台灣自己的「AI」模型(ChatGPT),不如好好的去收集歷史資料,想想怎麼維持一個有相對完整的歷史事件資料庫供人方便查詢,或是做好現在其實就有在做的各式闢謠網站(如
Mygopen)來的實際。
當然還有講到爛,但是實行上近乎無理的媒體識讀......
講是這樣講......不過實際上去看了一下他的完整訪談,我最大的問題還是「啊就沒必要花那麼多資源把他變成『AI』模型」這件事上
就算你用網路爬蟲爬資料(幹你Google、幹你OpenAI)去造模型,最後還是得靠人力一一去審
那把闢謠網站 AI 模型化並沒有比較省耶,新出的資料,甚至你合成完的資料還是要審啊。
還有,我並不認為開源就能等同於可靠,光看圖像生成模型的亂象就知道了。
 創作內容
創作內容







 ★===== 創作? =====★ (1)
★===== 創作? =====★ (1)