爬蟲Pixiv標籤並下載
思路:
標籤頁面返回每個作品ID
↓
用ID獲得每個作品的原圖連結、收藏數
↓
收藏數篩選
↓
把大於等於收藏數的圖下載

實作開始:
標籤頁面返回每個作品ID
↓
一開始我是苦於無法登入,而且無法登入的話就只能爬取前面10頁和沒有R-18
直到看到這位巴友的作品Yotsuba---Pixiv 爬蟲 有了這裡面的知識後就可以開始實作了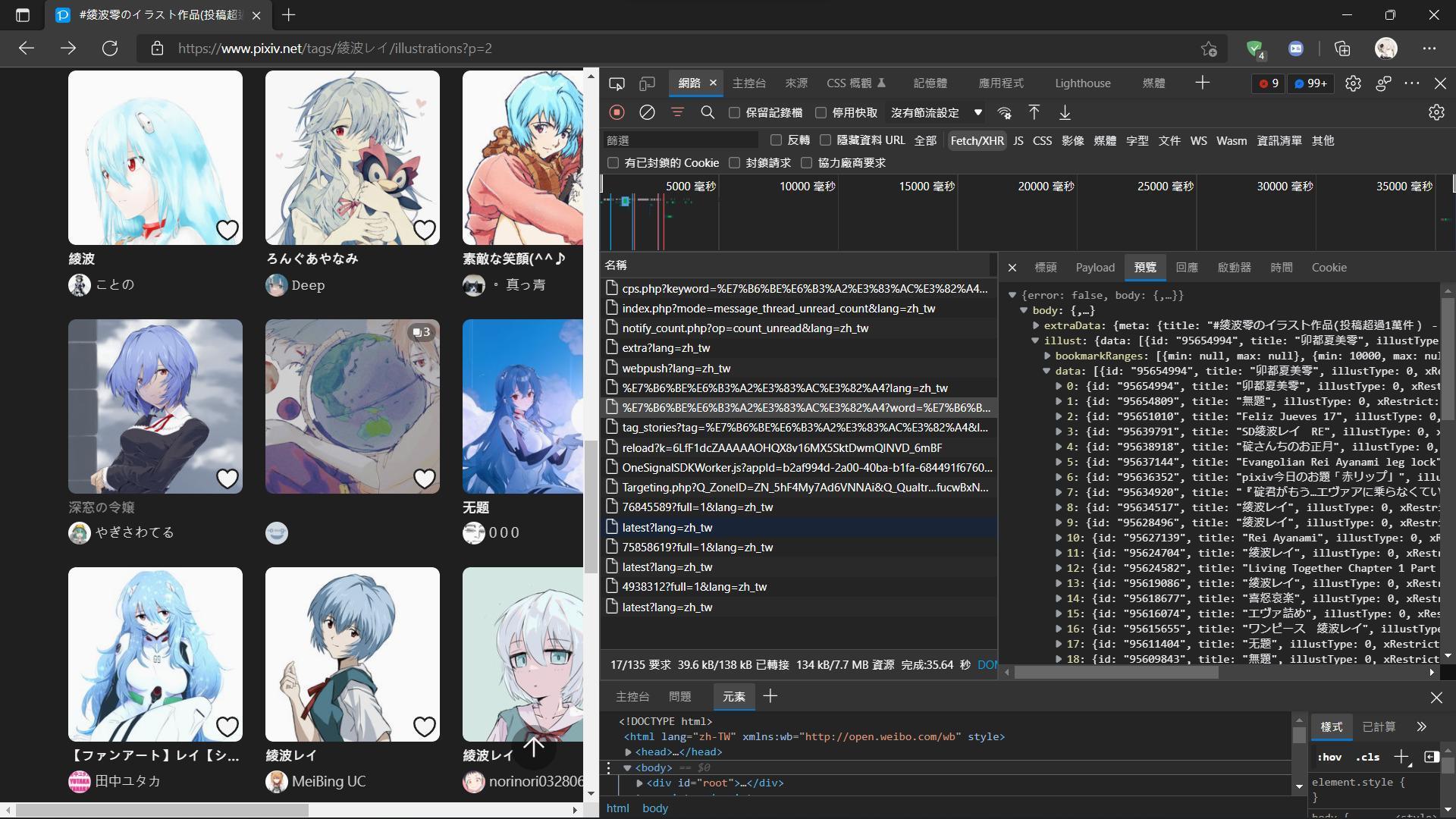
可以在這裡看到所有作品的id
而這裡是哪個網址呢
是這個
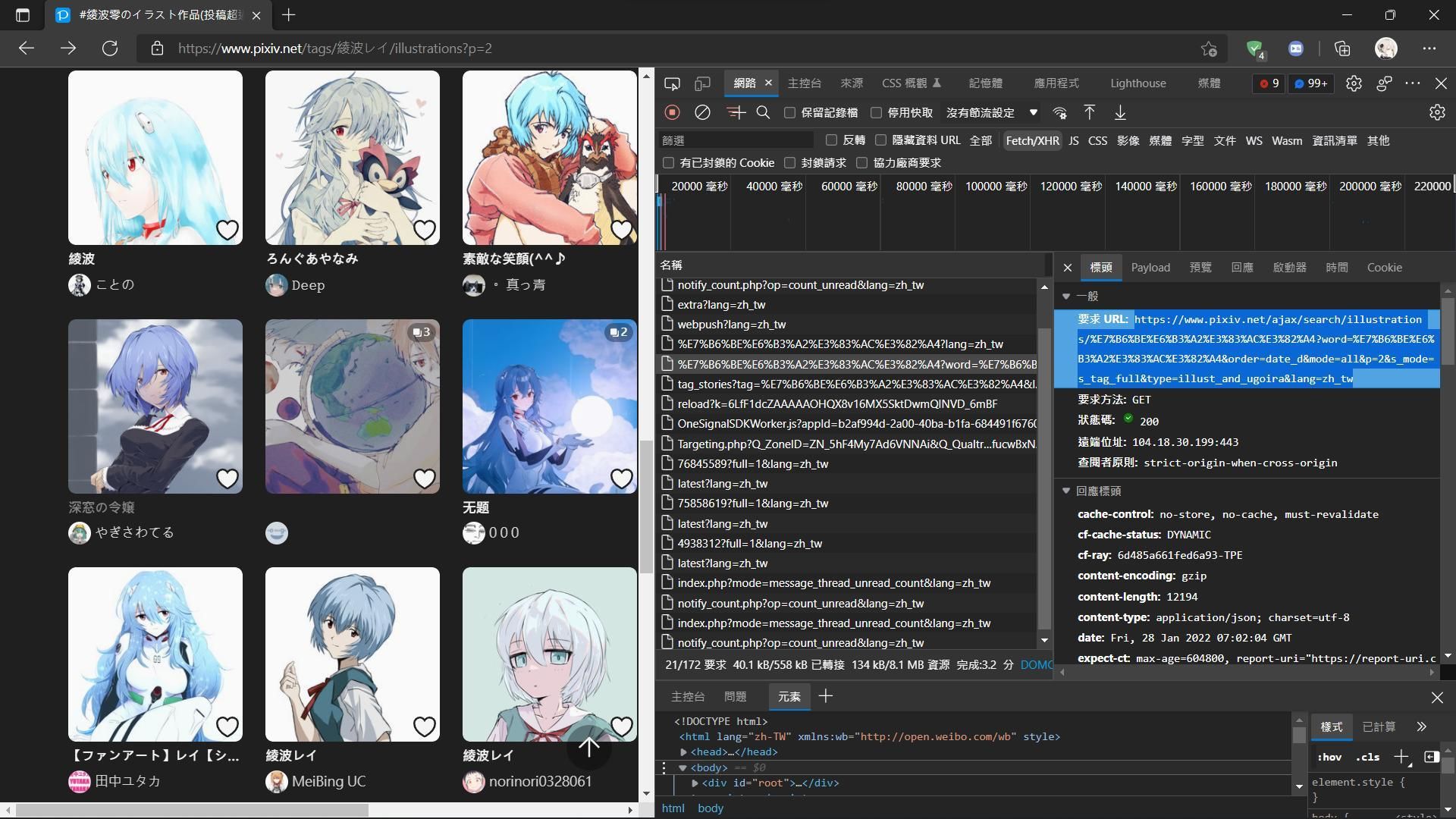
對他按右鍵→複製→複製為cURL (bash)

然後我們可以到這個網站:
把你剛剛複製的貼上去

就可以得到你要對網站傳送的資訊了
有了這些資訊後就可以得到你想要的id了
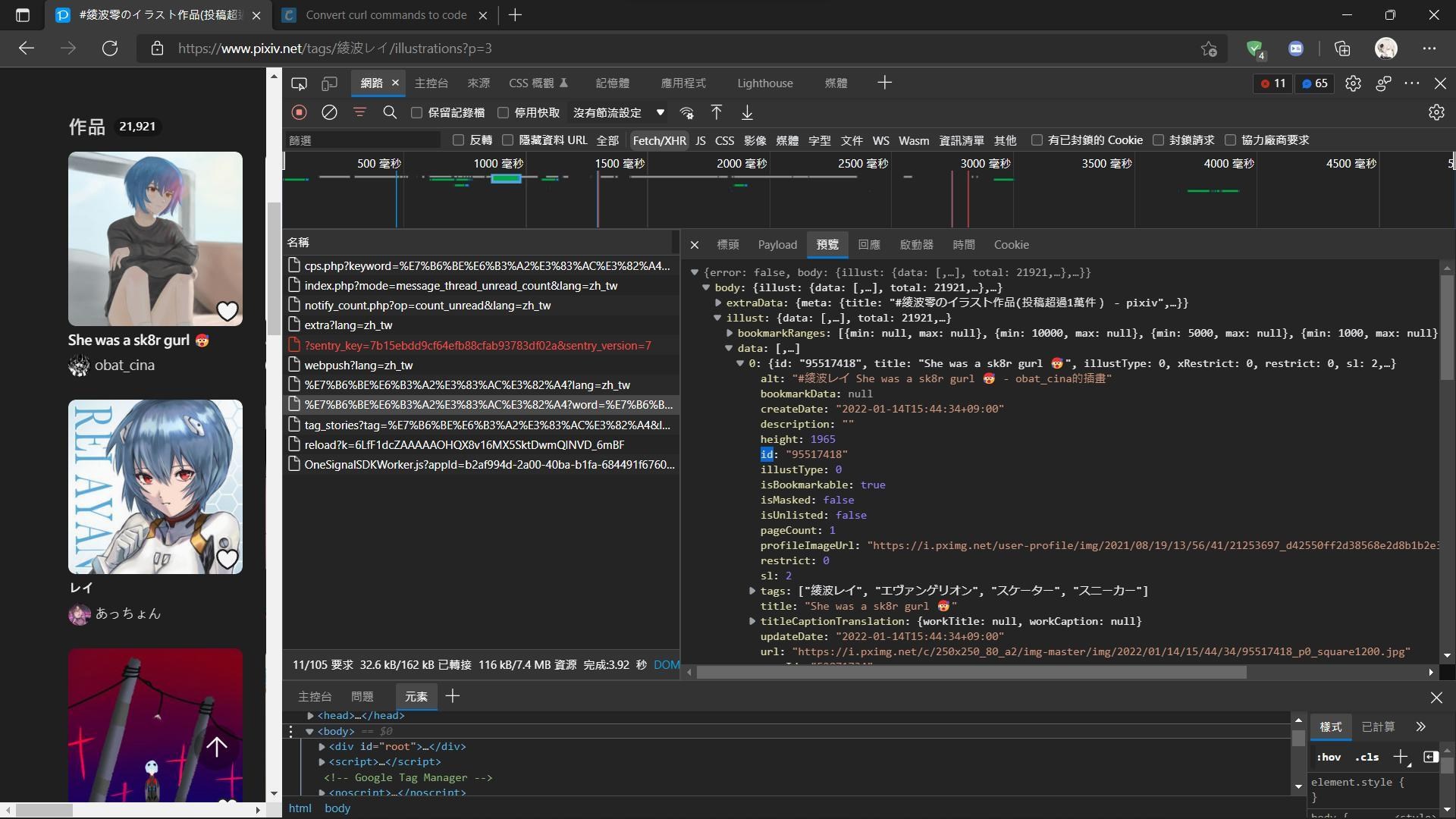
id在這:
['body']['illust']['data'][0]['id']
code:
| import json import requests from fake_useragent import UserAgent ua = UserAgent() headers = { 'authority': 'www.pixiv.net', 'sec-ch-ua': '"Microsoft Edge";v="95", "Chromium";v="95", ";Not A Brand";v="99"', 'accept': 'application/json', 'sec-ch-ua-mobile': '?0', 'user-agent': ua.random, #隨機user-agent 'x-user-id': '你的id', 'sec-ch-ua-platform': '"Windows"', 'sec-fetch-site': 'same-origin', 'sec-fetch-mode': 'cors', 'sec-fetch-dest': 'empty', 'referer': 'https://www.pixiv.net/', 'accept-language': 'zh-TW,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'cookie': '你的cookie', } tag = "綾波レイ" page = 1 paramsTag = { #請求標頭 'word' : tag, #標籤 'order': 'date_d', 'mode': 'all', 'p': f'{page}', #頁數 's_mode': 's_tag_full', 'type': 'illust_and_ugoira', 'lang': 'zh_tw', } urlTag = f'https://www.pixiv.net/ajax/search/illustrations/{tag}?word={tag}&order=date_d&mode=all&p={page}&s_mode=s_tag_full&type=illust_and_ugoira&lang=zh_tw' def getTagAllPicId(url, headers, params): listIllusts = [] #空串列 response = requests.get(url, headers = headers, params = params) #請求時的附帶資料 if response.status_code == 200: #如果請求成功 for i in range(0, 60): #每頁有0~59個id resdict = json.loads(response.content)['body']['illust']['data'][i]['id'] #print(resdict) listIllusts.append(resdict) #把每個0~59的id放到串列裡 return listIllusts artWorks = getTagAllPicId(urlTag, headers, paramsTag) print(artWorks) |
用ID獲得每個作品的原圖連結、收藏數
↓
正常直接從id頁面進去是沒有整個資料的網址的
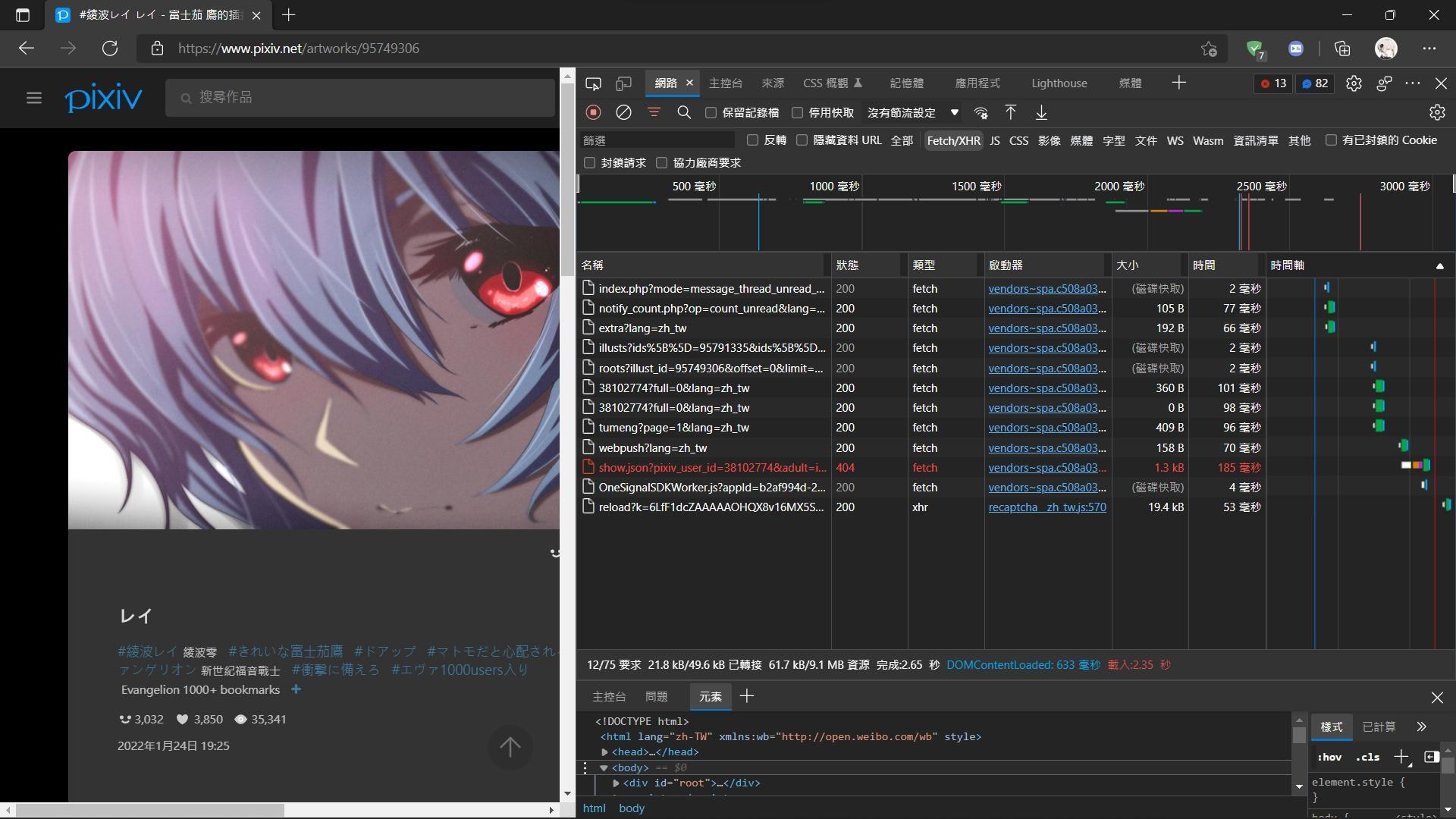
而我有一次從作者頁面進入的時候發現了有整個頁面的json檔!!!
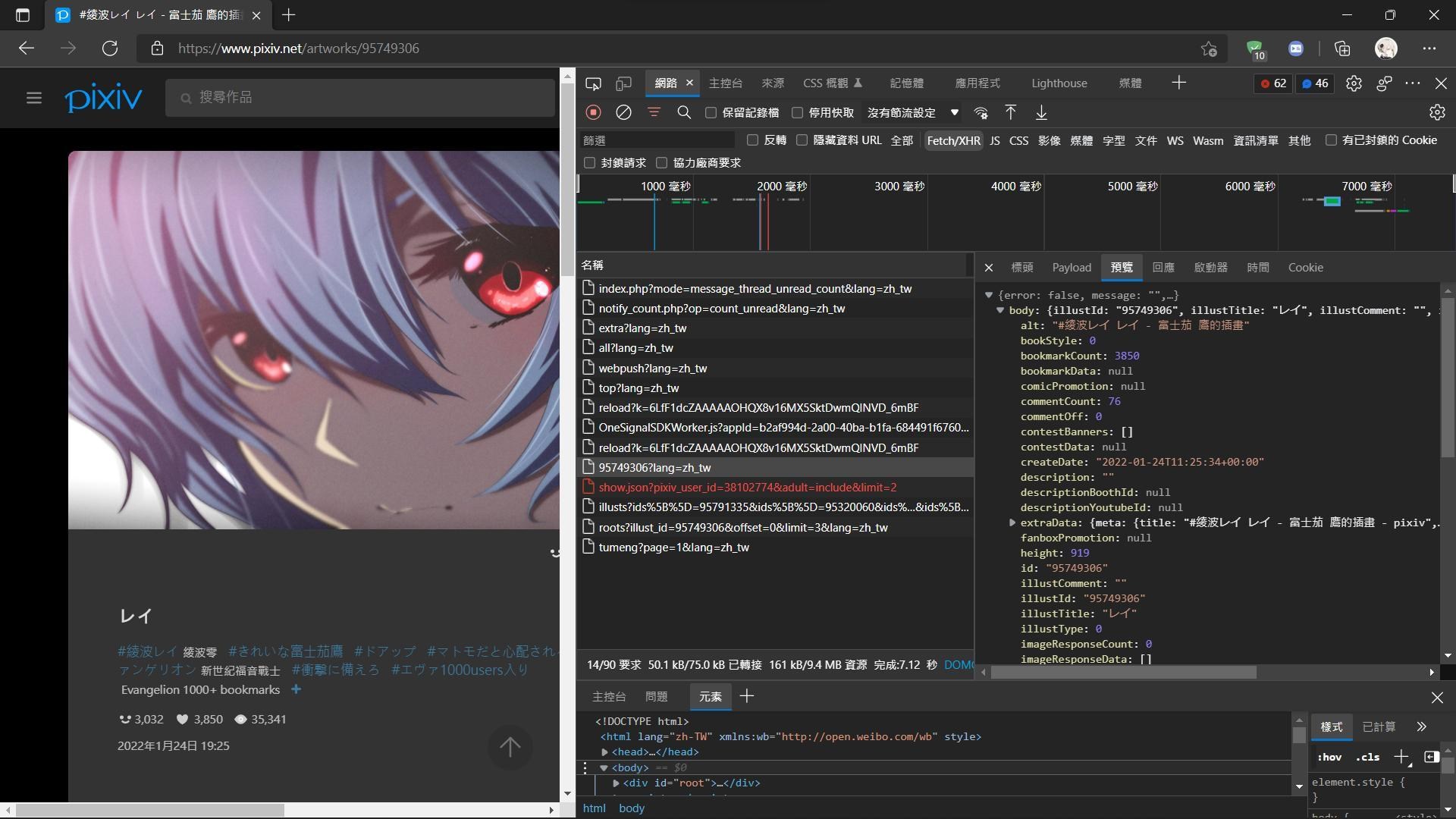
你知道這是多大的發現嗎
我之前還要用正則表達式去一個一個資訊配對,現在我只要對這個網址做請求就可以了,一切資料拿到手,資料有收藏數、原圖檔案連結,太爽拉
code:
| def getArtWorkPage(url, headers, params, setBookmark): response = requests.get(url, headers = headers, params = params) if response.status_code == 200: resdict = json.loads(response.content) artWorkBookmark = resdict['body']['bookmarkCount'] print(artWorkBookmark) if artWorkBookmark >= setBookmark: artWorkUrl = resdict['body']['urls']['original'] artWorkTitle = resdict['body']['title'] artWorkId = resdict['body']['id'] print("--------------------------------------------------") print(artWorkUrl) print(artWorkTitle) print(artWorkId) print("--------------------------------------------------") |
一口氣做完了獲得收藏數、原圖網址。當收藏數>=的時候才繼續,反之不繼續
接下來我又做了一個直接顯示圖片的程式
code:
| def artWorkShow(artWorkUrl, headers): response = requests.get(artWorkUrl, headers=headers) image = Image.open(BytesIO(response.content)) image.show() |
把大於等於收藏數的圖下載
↓
| def artWorkDownLoad(artWorkUrl, artWorkTitle, artWorkId, headers): os.makedirs(f"C://Users//Desktop//雜物//Pixiv//{tag}", exist_ok=True) #沒有這個標籤資料夾時創建一個 downLoadTitle = f"{artWorkTitle}-{artWorkId}" filePath = f"/Users/Desktop/雜物/Pixiv/{tag}" + "/{}.png".format(downLoadTitle) #存圖片的位置 with open(filePath, "wb+") as file: imgData = requests.get(artWorkUrl.format(artWorkTitle), headers=headers).content try: file.write(imgData) print("成功下載圖片: {}".format(downLoadTitle)) except Exception: print("未成功下載圖片: {}".format(downLoadTitle)) |
全程式碼:
| import json import requests from fake_useragent import UserAgent from PIL import Image from io import BytesIO import os ua = UserAgent() headers = { 'authority': 'www.pixiv.net', 'sec-ch-ua': '"Microsoft Edge";v="95", "Chromium";v="95", ";Not A Brand";v="99"', 'accept': 'application/json', 'sec-ch-ua-mobile': '?0', 'user-agent': ua.random, 'x-user-id': '你的id', 'sec-ch-ua-platform': '"Windows"', 'sec-fetch-site': 'same-origin', 'sec-fetch-mode': 'cors', 'sec-fetch-dest': 'empty', 'referer': 'https://www.pixiv.net/', 'accept-language': 'zh-TW,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'cookie': '你的cookie', } paramsPage = ( ('lang', 'zh_tw'), ) def artWorkShow(artWorkUrl, headers): response = requests.get(artWorkUrl, headers=headers) image = Image.open(BytesIO(response.content)) image.show() def getTagAllPicId(url, headers, params): listIllusts = [] response = requests.get(url, headers = headers, params = params) if response.status_code == 200: for i in range(0, 60): resdict = json.loads(response.content)['body']['illust']['data'][i]['id'] listIllusts.append(resdict) return listIllusts def getArtWorkPage(url, headers, params, setBookmark): response = requests.get(url, headers = headers, params = params) if response.status_code == 200: resdict = json.loads(response.content) artWorkBookmark = resdict['body']['bookmarkCount'] print(artWorkBookmark) if artWorkBookmark >= setBookmark: artWorkUrl = resdict['body']['urls']['original'] artWorkTitle = resdict['body']['title'] artWorkId = resdict['body']['id'] print("--------------------------------------------------") print(artWorkUrl) print(artWorkTitle) print(artWorkId) print("--------------------------------------------------") #artWorkShow(artWorkUrl, headers) #這裡可以選擇要不要把每個爬取到的圖片打開 artWorkDownLoad(artWorkUrl, artWorkTitle, artWorkId, headers) def artWorkDownLoad(artWorkUrl, artWorkTitle, artWorkId, headers): os.makedirs(f"C://Users//Desktop//雜物//Pixiv//{tag}", exist_ok=True) #沒有這個標籤資料夾時創建一個 #處存位置 downLoadTitle = f"{artWorkTitle}-{artWorkId}" filePath = f"/Users/Desktop/雜物/Pixiv/{tag}" + "/{}.png".format(downLoadTitle) #存圖片的位置 with open(filePath, "wb+") as file: imgData = requests.get(artWorkUrl.format(artWorkTitle), headers=headers).content try: file.write(imgData) print("成功下載圖片: {}".format(downLoadTitle)) except Exception: print("未成功下載圖片: {}".format(downLoadTitle)) #tag = "綾波レイ" #setBookmark = 1000 #setPage = 10 tag = str(input("請輸入標籤: ")) setBookmark = int(input("請輸入收藏數: ")) openPage = int(input("從第幾頁開始: ")) setPage = int(input("要爬取幾頁: ")) + 1 for page in range(openPage, setPage): print(f"第{page}頁開始,總共{setPage - 1}頁") paramsTag = { #請求標頭 'word' : tag, 'order': 'date_d', 'mode': 'all', 'p': f'{page}', 's_mode': 's_tag_full', 'type': 'illust_and_ugoira', 'lang': 'zh_tw', } urlTag = f'https://www.pixiv.net/ajax/search/illustrations/{tag}?word={tag}&order=date_d&mode=all&p={page}&s_mode=s_tag_full&type=illust_and_ugoira&lang=zh_tw' artWorkIllusts = getTagAllPicId(urlTag, headers, paramsTag) for i in range(0, 60): urlIllusts = f"https://www.pixiv.net/ajax/illust/{artWorkIllusts[i]}?lang=zh_tw" getArtWorkPage(urlIllusts, headers, paramsPage, setBookmark) print(f"第{page}頁結束,總共{setPage - 1}頁") |
展示影片: