前言
在爬蟲的世界中,你是需要在網路的世界遊走的,那你就要知道一些江湖的規則...痾我是說背後的傳輸方式。而在你看到這龐大的網路世界中,在網路這一塊大多是使用一個叫做 Http 的傳輸協定,這篇只會提基礎的,http socket、https 那些可以自己研究。在這地方可能會些許無趣,但是學會了你會對網路有更深的理解。
Http 簡介

Http 全名 Hypertext Transfer Protocol,他是一個應用層的傳輸協定,底部是由 TCP — 一個傳輸層協議所構造起來的,這些不懂沒關係,你只要知道應用層是網路層級中最高的,也就是最接近我們使用者的就可以。
除此之外 Http 是一個無狀態 (stateless) 的傳輸協議,你在網路中做的事情對於 Http 來說都是單一獨立的事件,彼此間互不關聯。
「不對阿,那我們平常網頁不是都會記錄我們的登入狀態嗎?」
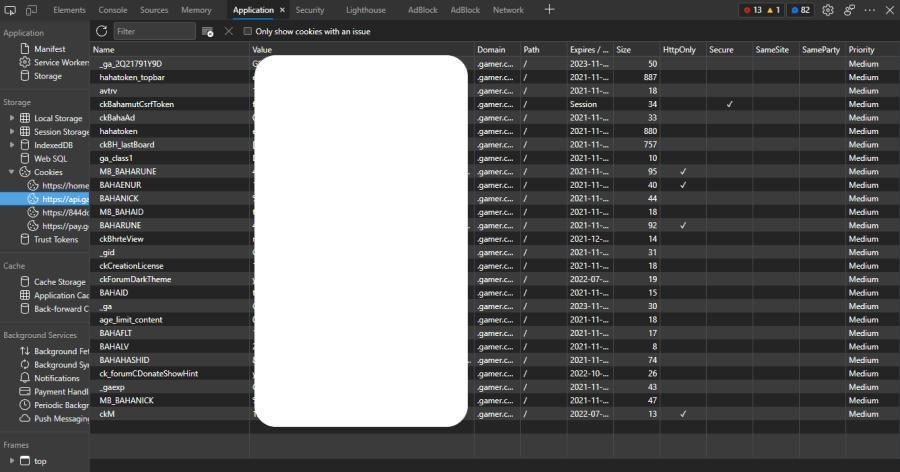
其實平時網頁暫存一些登入資料並不是使用 Http 的功能,而是瀏覽器的 cookies 來存儲。這也是為什麼有些網頁會問你要不要儲存 cookies,方便紀錄你未來使用這個網頁的其他功能。Cookies 是有時限的,所以通常巴哈過一段時間就需要重新登入就是因為這個原因。
要查看 cookies 可以使用瀏覽器的開發人員選項 F12 → Application(應用),左邊的 storage 應該可以看到 cookies。
Http request (網頁請求)
▏HTTP 傳輸協定中,可以分為客戶端 (Client) 和伺服器端 (Server),而在這個協議裡頭,客戶端是主動的,他通常會向伺服器發送一些請求 (Request),相對的伺服器端是被動的,他會根據客戶端的請求來回傳不同的回應 (Response)。

在請求中又可以分為 8 種 method (方法),但在一般情況我們只需要會兩種就好,分別是 get 和 post,其他的很少看見 (至少我還沒碰過)。
首先 Get 是不允許在 http request body 內放資料的,所以一般 Get 功能都是根據 url 後面接著的參數,用來取得一些普通的資料,例如巴哈的文章有哪些、哪些版的進版圖,或者是我上一篇自己簡單架的新聞查詢 API。然而如果一個網頁是用 Get 來實作登入功能的話,這意味著你的登入帳號密碼都會被連接在 url 後面,會有很大的安全疑慮。
Post 則是可以在 http request body 內放入一些資料(密碼、登入資訊),url 就可以只放請求的位置,相比於 Get 稍微安全一些。Post 的出現也常伴隨著在網頁中 <form></form> 的出現,只要有網頁表單要送出,幾乎都是使用 Post 來請求。
Http 的請求訊息可以大概切分成兩部分,一個是 header (標頭),一個是 body (軀幹)。Header 裡面又可以細分很多小項目,其中有幾個在爬蟲裡面是非常重要的:
- User-agent: 你的瀏覽器版本、名稱、作業系統 ... 等資訊,這個重要是因為許多網站會利用這點來把沒標示 User-agent 的機器人給過濾掉,如果不想被過濾掉,那麼你的 http 請求裡面就要附上 user-agent 這個值。
- Content-type: 指網頁伺服器那邊回傳的資料格式,如果不對的話,程式會出問題。
- Cookie: 你的 cookie 附上了就可以讓伺服器知道你現在的使用狀況是什麼(例如你上次登入的是誰的帳號,可以直接繞過登入)。
至於 body 則是依據接受的表單不同,而有不同的值要填,例如你要登入一個網頁,那麼你的 http request body 可能就會有 { "account": "your account", "password": "your password" },觀察 body 內部要填入什麼也是爬蟲的一環,一般可以透過 html 的 form tag 來找到線索。
以上我所提可以在開發人員工具 F12 → Network(網路) 重整後可以看到。
Http response (網頁回應)
在伺服器端接收並處理完一個請求後他就會回傳一個 response,在 response 裡面有一個狀態碼,每個狀態碼都有相對應的含意,這邊就簡單列出幾個,詳細的可以在維基百科找到。
- 200: success,請求成功
- 302: found,轉址、重新導向
- 400: bad request,伺服器看不懂請求
- 404: not found,找不到網頁
- 500: internal server error,伺服器內部問題
- 505: http version not support,http 版本不支援
當請求成功時,回應的內部就有相應的資料,可能是 html、json 檔、一串文字等,取得資料後再根據資料格式來處理資料,也是爬蟲的一個環節唷!
總結
認識 Http 後對於我們爬蟲有頗大的幫助,當你熟悉了這些東西,你要爬網頁時你就知道要從哪裡看起,哪些網頁要用什麼方法、哪些網頁不能用什麼方法、甚至使用模擬登入來模仿真實使用者的動作。下一篇會開始介紹 Python 裡面的 requests 的一些常用功能。