雖然這個領域似乎挺冷門的,不過還蠻多有趣的可以玩,以我們實驗室來說,近年有在做基於 LLVM 的 Binary Translator 來 Support RISCV,Apple M1 現在你可能會用到的 Rosetta2 就是一個 Binary Translator,而現在我們實驗室主要就是在做多面體編譯(Polyhedral Compilation),所以我來談談多面體編譯是怎麼一回事。
多面體編譯顧名思義就是要編譯多面體,大致上可以分成三個 stage。
- 分析出程式中符合某些特定語意條件的段落,轉換成多面體模型
- 針對多面體模型透過調度算法進行優化達到平行或是提高程式 Data Locality
- 根據目前的多面體模型設計 Code Generator 轉換到目標硬體,像是加速器、GPU 或一般的 CPU
像我們現在是在做轉換到 GPU 程式過程中的多面體優化,也有在做 MLIR 相關的研究。這邊我們就舉一個小例子,以 Jacobi-1D 為例。
| for (int t = 0; t < T; ++t) for (int i = 1; i < N-1; ++i) A[(t%2)+1][i] = 0.333 * (A[t%2][i-1] + A[t%2][i] + A[t%2][i+1]); |
如果今天目標是在 CPU 上,會怎麼去優化這段程式,一個非常直觀的就是把 loop i 給平行了,因為 loop t carried 了所有的 dependence,所以你不可能平行 t,所以我們把 i 平行的話程式就會變成:
| for (int t = 0; t < T; ++t) parallel for (int i = 1; i < N-1; ++i) A[(t%2)+1][i] = 0.333 * (A[t%2][i-1] + A[t%2][i] + A[t%2][i+1]); |
但這段程式有個缺點,你 parallel loop i 的話是要怎麼平行?一個簡單的做法,直接下 omp pragma,讓他幫你處理,但有沒有可能再挖掘一下 Data Locality?有,我們對 loop i 做 Tiling,然後將外層 Tile 的部分平行,這樣平行的同時,每個 Thread 在計算的時候也能兼顧 Spatial Locality。
| for (int t = 0; t < T; ++t) parallel for (int bi = 0; bi < (N-2)/32; ++bi) for (int ti = 0; ti < (N-2)%32; ++ti) A[(t%2)+1][bi*32+ti+1] = 0.333 * (A[t%2][bi*32+ti] + A[t%2][bi*32+ti+1] + A[t%2][bi*32+ti+2]); |
但再想一下,有沒有可能挖掘到 Temporal Locality?如果想挖掘 Temporal Locality,看起來好像沒辦法,因為如果對 Loop t 做 Tiling 的話,你就會出現循環 Dependence。為了能先解釋這一部分,我先介紹一下多面體模型的其中一個項目:Iteration Domain,其中多面體編譯是以一個 statement instance 為單位,所謂的 statement 就是其中你在上面看到的那一段 A[..][..] = ... 就是 statement,而 statement instance 指的就是根據在其循環結構下的其中一個情形就是 statement instance,例如我們把 Jacobi 1D 的 statement 稱作 S,那第一個執行和最後執行的 statement instance 分別是 S(t,i) where t = 0 and i = 1 和 S(t,i) where t = T-1 and i = N-2,所以在所有的 statement instance 構成的集合就叫做 Iteration Domain,雖然還有一些組成條件,不過那樣對基礎介紹有點太多了,所以略過。
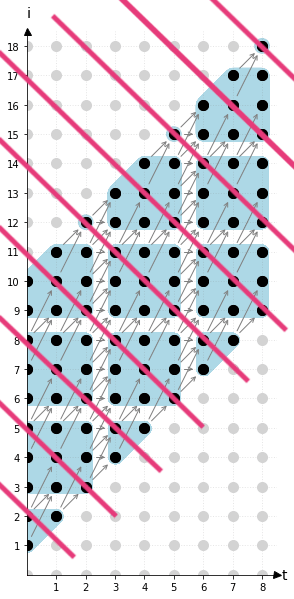
所以我們可以把一個程式表示成一堆點的集合,以上面 Tiling 違例,假使我們今天 tile size 不是 32,是 3,那他構成的空間會像下面這張圖,灰色線代表的是 statement instnace 之間的依賴(Dependence),而黑色的點但表的是 statement instances,座標系就是由他的 Loop iterator 構成。

回到我們剛剛的話題,如果你對 Loop t 做 Tiling 會發生什麼事?也就是藍色的區塊會沿著 t 變大,這時候就會發生原本我們可以對相同 t 上的每個 block i (藍色區塊)平行執行,但現在因爲你對 t 做 Tiling 了,每個區塊會跟隔壁的區塊同時有灰色線互相依賴,這樣每個 block 就有衝突,不能夠同時執行了,也不能決定誰要先執行了,因為互相依賴。
有沒有什麼辦法可以解決這個問題?有!我們把這個形狀稍稍做點變化,不如我們把 loop i 變成 loop i + t 如何?這也就是所謂的 Loop skewing,他就會變成下面這張圖,每一條紅色線上的 block 都是可以平行執行的,這樣你就同時有了平行性還有 Temporal/Spatial Locality,但這樣夠好了嗎?NO,還有更好的。
有沒有可能有一種形狀,我們可以讓平行性更好?因為如果看上面那張圖,你會發現好像開頭跟結尾都沒辦法充分利用到平行性,第一條紅色也就一個可以平行,到第三條紅色線,才有兩個 block 可以平行,不管怎麼樣,平行性好像差很多,我們可不可以有個更好的形狀然後有 Sptail Locality、Temporal Locality 還有更好的 Parallelism?有!我們把它做成菱形看看,原本的 Loop t 變成了 Loop t - i ,Loop i 變成了 Loop t + i:
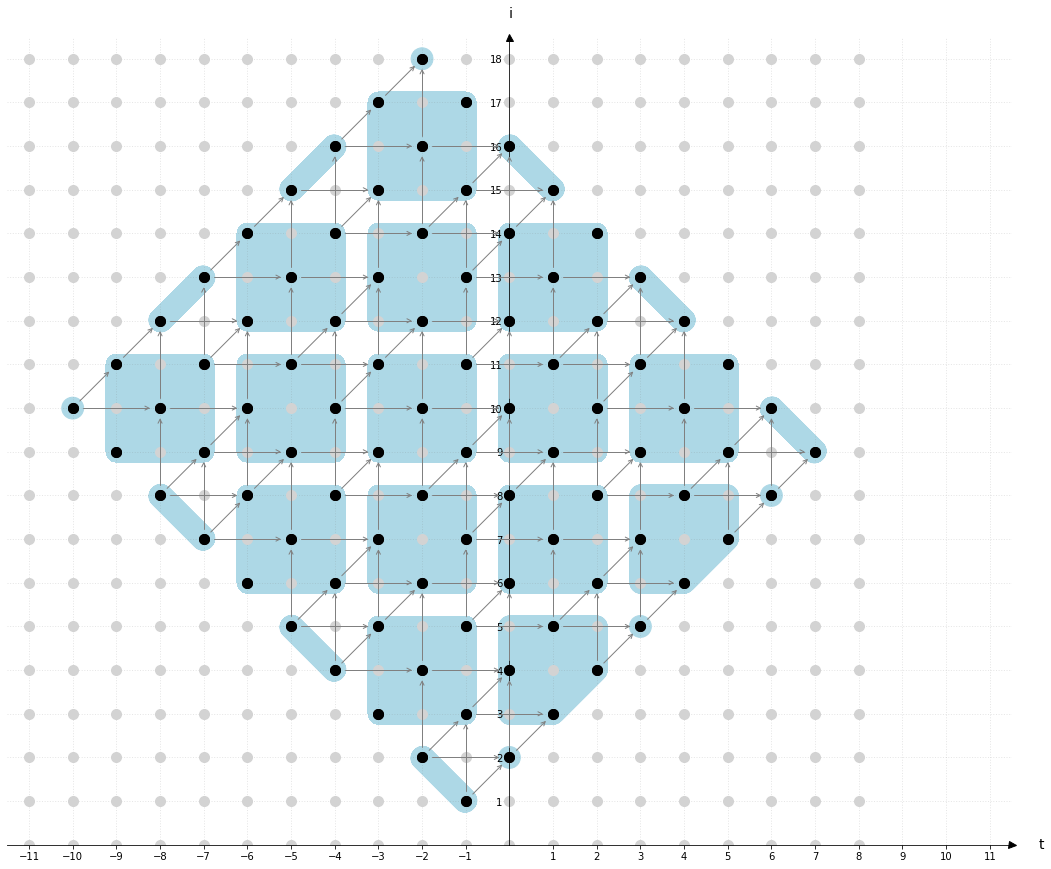
這下你會發現某個角度上的所有 block 都是可以平行執行的。
多面體編譯其中一些研究就是在玩弄這些形狀,然後將他們對應到計算上,前面說到的 Iteration Domain,那我們要怎麼變成像上面這些東西,在多面體編譯中,Loop tranformation 一類的操作其實都是靠我們將 Iteration Domain 上的點對應到某個特定的時間(timestamp)上,如此一來我們可以用這些不同的時間來表示這些點上誰要先執行誰要後執行,或是哪些點是在同時間上,這樣就可以平行,以 Tiling 來說,我們就決定好 Tile Size 然後將對應維度的時間去做操作。
原本 S(t,i) 會對應到 (t,i) 這個時間點,對 i 做 Tiling with tile size 32 的話就可以表示成:S(t,i) -> (t, i/32, i%32),就這樣,這就是在多面體編譯上面要如何去表示每個 instance 時間的方法,以這樣表示的主流工具是 ISL,他統合了多面體編譯的各個面向以及 Scheduling,像是整合了早期的 Feautrier 算法和近年的 Pluto 算法,本質上我們在做這樣自動調度的算法的設計是針對你所在意的問題構成一個 ILP 的問題,再透過工具進行求解,得到一個調度的變換矩陣。
而所謂的調度(Scheduling)就是玩弄這些時間點,然後將他們對應到你想要計算的 Hardware 上,像是 GPU,或者是各類加速器,當然這邊需要對 Code generation 做不少事情就是了。以上算是一個簡單的多面體編譯介紹,網路上其實有蠻多介紹了,這邊就只做一點粗淺的介紹而已XDD。