想解UVa Online中較簡易的一題
正巧發現一個很有意思的題目,雖然可以硬解
而且硬解對效能應該是較理想的
但我已經過了比解題速度的年齡跟求職階段
而且老實說那題網路上幾乎只找得到硬解的解法
就慢慢解吧
雖然一星期是太久了些沒錯
不過最近這星期也有些事情
(明天-也就是星期天上午家族聚餐,所以最快可能星期一有動作或用實況時間研究)
回正題:
排列,也就是數學的P
這邊特別指 全排列
全排列在解決的問題或說描述的現象就像是
1 2 3 4順序能任意調換,總共有幾種不重複的排法?
答案是4! = 1*2*3*4 = 24
但這數字答案對人類比較有意義
電腦能做到更多事
像是把那24種解法全數列出來
若有程式需要對每種狀況做運算
就能用上全排列了
像許多數學謎題需要用上1~9等固定範圍全部的數字
就適合用寫全排列程式讓電腦暴力把答案算出來
全排列有很多種實作方式
其實以前也算在資料結構有學過
不過沒學得很好
現在再重來一次
其實解全排列概念很簡單
就照順序固定第一個數字,把後面的對調完後
再換個數字,再把後面的對調
只是要轉成程式敘述要想得很清楚
目前掃過的幾種解法原則上都是遞迴解決
概念也幾乎一樣
但結果有些會有差異(有沒有照數字或字母順序)
而有些寫法會比較好記、好懂些
然後大概會介紹下C++的std::next_permutaion();
其實那可能也沒什麼好介紹的
就注意使用前要先排序過
像std::sort();
由於使用前要先排序過
有些限制在
還是自己學著如何在短時間內完成全排列實作較好
使用起來大概就像這樣(抄襲至網路)
std::string s = "abcde";
std::sort(s.begin(), s.end());
do {
std::cout << s << '\n';
} while(std::next_permutation(s.begin(), s.end()));
需要
#include <algorithm>
#include <string>
由於有std::cout,自然還要
#include <iostream>
若改成陣列寫法要注意的是
std::sort跟next+permutation第一個參數就是陣列名稱或陣列名稱+0
也就是陣列要採指標表示法
至於第二個參數,是陣列最後個元素再後面一個,也就是要超出陣列內容範圍
假如陣列大小是N
那第二個參數就是 陣列名稱+N
通常提到全排列程式
之後就會講到組合(也就是C幾取幾)與重複元素的排列
順利的話是希望這些能一口氣解決掉
附帶一提
列出組合的全部可能
Prolog-99 problems跟Haskell-99 problems
是在第26題
有興趣的話不妨看看解法
雖然解法概念原則上沒變
但寫法簡潔許多
(...之後內容改天補上,先把手邊的全排列解法理解、記熟再說)
首先來談一下
「為什麼排列(permutation)需要排序(sort)」?
嗯...這樣問有點突兀
那先來談下"空間"複雜度,也就是佔的記憶體空間好了
常見的permutation實作方式是遞迴
因為每次遞迴,都需要將程式壓入堆疊呼叫新的
也就是空間複雜度是與次數相關,記為O(n)
big-O代表的是考慮最差情況下的複雜度
n是用來代表數量級,而n本身的意思是執行次數或者說輸入個數
數量級只要紀錄最高的就好
像若巢狀遞迴(遞迴中還有遞迴)的話
空間複雜度是...
不對,遞迴原則上只能一層
因為遞迴呼叫到最後會慢慢return回來
巢狀遞迴應該是不可行的或很難想像
注意二階遞迴跟巢狀遞迴是不同的
二階遞迴是像費式數列1 1 2 3 5 8 13 ...那樣,會用到兩個遞迴結果
一階遞迴就像是階層,也就是n!-1連乘到n
原則上來說程式會用到遞迴時
大多就是想避開很複雜的巢狀迴圈狀況才用遞迴簡化
若連遞迴也是巢狀的就失去意義
(而且巢狀遞迴的空間、時間複雜度應該都很驚人)
那,只好舉老例子,雙層根據輸入數量來跑的迴圈
時間複雜度是O(cn² + cn + c)
常數c與最大項以外的是可以忽略的
可以簡記為O(n²)
時間複雜度就想成、類似程式執行的次數
雙層迴圈像九九乘法表
就要跑9²次,也就是81次
若是二十二十乘法表(聽說是印度在背的)
就要跑20²次,也就是400次
所以可以看出大概是O(n²)
時間、空間複雜度部分
可參考網易公開課-麻省理工學院 算法導論中英雙字幕翻譯影片-第一堂課
(英文好的話就不用看中文翻譯啦!!我是英文不好的)
通常寫程式比較關心的是時間複雜度
因為在記憶體越來越大、便宜的狀況下
以個人電腦程式來說比較關心的是速度
其實記憶體(主要指暫存器、主記憶體)越來越大、便宜倒也未必
有個原因是,早期記憶體很小的狀況下
發展了現在絕大多數的經典演算法
因此現在就比較不會有捉襟見肘的狀況
但程式沒設計好時還是會碰上記憶體不足的問題
(較常見的是記憶體洩漏,也就是記憶體釋放操作失誤,導致占用記憶體量逐漸增大的情形)
麻省理工學院 算法導論中英雙字幕翻譯影片網誌在
影片差不多在51分鐘的地方有提到
在早幾分鐘前則是在談
採用這種表示法的原因是想去除程式執行的硬體環境差異而導致的執行時間差異因素
一個僅有一層遞迴的程式,用的變數越多
理論上空間複雜度是O((變數數量+1)*n)
其實我也不知道我寫得對不對
我的想法是,遞迴呼叫要+1,是因為函式本身存入堆疊算一次
然後每個變數,分開儲存在各個遞迴呼叫,所以一個就1n
但通常比較不關心數量級的具體係數啦
因此O(c),O(1)與O(n),O(3n)分別是可以視為O(1)、O(n)的複雜度
在命令式語言中,若能把遞迴去掉,就能大幅降低空間複雜度跟些時間複雜度
permutation的非遞迴寫法在
中的Possible implementation(可能實作方式)底下
stackoverflow也有相關討論
我還不是很懂所以暫時不提
但程式中會發現
if (*--i < *i1)
這代表用C++的std::next_permutation(,)
一定要經過排序,而且是由小到大(升冪,ascending)的排序
本來我是不想用一定得排序(sort)的排列(permutation)
但我測試了幾種輸入狀況後
有排序的排列確實擁有巨大優勢
就像是未經排序的資料原則上只能透過
1.循序搜尋法(暴力法,從頭比對到尾或從尾比對到頭)
2.hash table(雜湊表,散列表,哈希表)來搜尋
(hash table在沒排序的資料上搜尋,
理論上應該還是採用循序搜尋法,學的不熟這邊不太確定,不過還是提一下好了
常見的文件MD5碼,就是一種hash table應用,雖然是計算整個檔案的雜湊值
雜湊的常見應用還有網站儲存用戶密碼)
由於時間因素
下次就提下常見的排列(permutation)遞迴實作法
然後說下為什麼經過排序(sort)後比較好
或者說不排序(sort)的話
排列程式哪邊、哪種狀況難寫
簡單來說就是資料有重複時
因為會想盡可能的減少記憶體使用量
因此似乎只能靠排序(sort)過的排列(permutation)了
現在來介紹全排列(permutation)第一種做法
這做法非常好記
但缺陷也十分明顯
例如:要去除重複排列(permutation)的代價高昂,連排序(sort)都救不了它
以下程式非常常見
但我主要抄襲、節錄自
#include <stdio.h>
#include <string.h>
void swap(char *x, char *y)
{
char temp;
temp = *x;
*x = *y;
*y = temp;
}
void permute(char *a, int l, int r)
{
if (l == r)
{
printf("%s\n", a);
}
else
{
for (int i = l; i <= r; i++)
{
swap((a+l), (a+i));
printf("before %s \t i=%d \n", a,i);
//輔助理解執行順序用
permute(a, l+1, r);
swap((a+l), (a+i)); //backtrack,或者說回復成原狀用
printf("after %s \t i=%d \n", a,i);
//輔助理解執行順序用
}
}
}
int main(void)
{
char str[] = "ABC";
int n = strlen(str);
permute(str, 0, n-1);
return 0;
}
如果只看permute的話,這程式非常好記
所以只要注意下它的缺點即可
這方法的執行順序大概是
abc
acb
還原成abc之後,1與2對調(也可以說是索引值0,1對調,陣列的話就像a[0],a[1])
bac
bca
這邊問題都還好
但接著還原成abc後,是1與3對調(陣列表示的話即a[0],a[2]對調)
那這會發生什麼事呢?
cba
cab
最後再恢復成原狀abc(當然這不會印出來)
通常我們會希望一全排序程式不會破壞原先的架構
換句話說
它不按照字母順序列出全排序
但這又有什麼關係呢?
目的達成不就好了?
我本來也這麼覺得
但...
沒錯,還是能印出全排列
但這僅限於各元素不重複的狀況下
若重複的話,不再另外開陣列,是很難去除重複狀況的
(而遞迴要額外開陣列是很困難的事情,很有可能得獨立個函數來處理這件事情)
雖然嚴格上來說,全排列本身就不用考慮重複狀況
所以才叫"全"排列
但若我們是要用全排列程式來解題
碰上有些能減少計算量(也就是具有重複排列情形)的狀況時該怎麼辦?
知道下還是好的!!
(雖然要克服這種狀況,目前見到的每個解法都需要破壞(排序,sort)目標陣列的原貌)
為什麼說很難去除重複狀況呢?
請看好
若改成char str[] = "ABB";
出來結果
ABB,BBA也許還能削掉,因為相鄰,理論上有機會削掉
但BAB跟第二個BAB之間,天人永隔
上述說法有點問題
主因是這方法不照字典順序(更準確來說是索引值)排列的關係
所以重複情況出現的情形,其規律相對晚些談的其它做法沒那麼好找、削除
要去除掉那重複情況
大概要把各種排列狀況直接存入陣列或者記錄其hash值
可是若這麼做
有N個元素就有N!種排列方式的話
要有N!個陣列或N!個整數變數來記錄hash值
空間複雜度上會有困難
也就是會在輸入極小的情況下耗盡記憶體
更別提排列時,到後期還要比對將近N!個陣列或N!個hash值
這部分也會讓時間複雜度大幅增加
因此這方法的價值主要是在於
這是個很簡潔的遞迴寫法可以實現全排列
絞盡腦汁後還是寫不出排列程式的話
還是很有價值的
面試時也可能會用到
不過面試時若真的是這題
要能勝出其它的競爭對手
除了這簡潔遞迴方法、C++ STD的現成函式與實作原理外
可能還需要其它的解法
才能鞏固自己的面試優勢
接下來就要祭出這兩個網站了
這兩個網站的內容基本上類似
但兩邊都看蠻有幫助的
互相補足對方沒提到的內容
演算法筆記↑
看這兩個網站會感覺到
臺灣這領域其實還是有人在的
(雖然臺灣軟體領域一直以來都有人在,像甲尚科技
不過...學習時很少看到相關中文資料
所以就沒什麼感覺)
哦,對,解全排列雖然大多是遞迴解法
但這些遞迴解法用演算法分類可以細分為backtracking(回溯法)
算一種迭代(窮舉,迭代通常又指迴圈,見
維基百科)各種可能的思路之一
也就是brute-force algorithms暴力法的一種
其實暴力法就是窮舉法,善用電腦運算與儲存能力的一種解題方式
雖然有時有些人會把手動列出所有情況也算做種暴力法
但嚴格上來說人工列出所有情況不算暴力法啦
比較算"硬解"或者說特解(像微分方程的感覺)
先從這個解法開始講好了
由於這解法有搭配Stanford大學的影片
因此以下就稱為Stanford解法(當然正式名稱我不知道)
從這解法開始講的原因是
這解法有很明確的圖表
以及呼叫了許多函式與使用字串
能簡化、避免些C語言、C++程式規範的干擾
(該網頁還是用Javascript實作,就離程式細節更遠,也可以說更抽象了)
所以這邊給C++實作法
其實跟課程影片的解法是一樣的(課程影片中投影片解法就是用C++)
#include <iostream>
#include <string>
using namespace std;
//這樣等下各指令就不用std::string了
void recPermute(string soFar,string rest)
{
//C語言、C++中,變數沒指定值就使用會有嚴重錯誤
//由於是用之前的記憶體殘留值,出來的結果會很奇怪或者是"應用程式已停止回應"
string check_repeat="\0";
string next="\0";
if(rest == "") {
cout << soFar << "\n";
} else {
for(int i = 0; i < rest.length(); i++) {
check_repeat = next;
next = soFar + rest[i];
//由可選擇取一,與目前所選擇組合(字串串接)
string remaining = rest.substr(0,i) + rest.substr(i+1);
//移去已取出的 rest[i]
if(next != check_repeat)
recPermute(next, remaining);
}
}
}
int main(void)
{
recPermute("","DCBA");
//使用起來像這樣
return 0;
}
如果僅是要實現全排列的話
有check_repeat(檢查重複)的每一行都可以去掉
那算是抄襲或者說融合自演算法筆記的程式內容
我們可以發現
StandFord解法比起C++ STD提供的next_permutation的優點是
可以升冪(next_permutation要求升冪,由小至大)或降冪(由大到小)排列
如果只是要全排列的話
可以完全不排序
↑這就是next_permutation所做不到的
可是next_permutation因為假設排列(permutation)目標已經排序(sort)過了
所以可以用非遞迴解法
空間複雜度、時間複雜度相比是有很大改善的
那為什麼這解法還要排序(sort)?
就用這狀況吧
recPermute("","BABA");
我們把運行結果貼到notepad++或者是任一個有行號的編輯器
excel或open office math表格也是可以
結果是16個,這有沒有重複呢?
首先4個不重複的全排列有4!=1*2*3*4=24種排列方式
而兩個兩個重複的一組,兩個本身可分別視為種排列方式
因此4!/(2!*2!)=24/(2*2) = 6
應該是只有6種排列方式
不用刻意檢查也知道有重複排列
再回頭看一下程式
每次進迴圈時check_repeat = next;
next = soFar + rest[i];
也就是check_repeat的運作原理是
只跟上次的排列結果比對是否一樣來判斷有沒有重複排列
Stanford做法能順利運作的原因是
順序是固定的
若字母按照順序排序過
排列出來的結果也會是按照字母順序
(因為這解法其實算是按照索引值排列)
因此會重複排序的情況都是緊緊相鄰的
只檢查上一個就可以
不像上個解法permute(a,l+1,r);
畢竟permute(a,l+1,r);本來就是只印全排列
因為它不是按照字母(索引值)順序
所以不能用與Stanford解法只記錄前一種排列來去除重複排序的情形
我們可以用
recPermute("","AABB");
recPermute("","BBAA");
recPermute("","YOOO");
...等等
來看去除重複排列是否正常運作
去除重複排列這邊不太好講、不太好想
但因為程式是對的
所以就算理解、說法不對也沒什麼關係,也許還有助於記憶
我目前想到的講法有些複雜
看日後能否有所改良
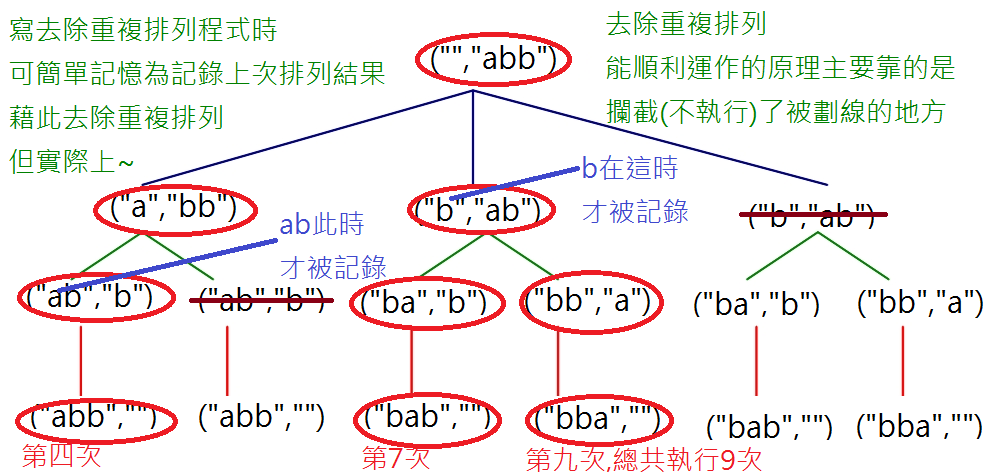
為了講解方便,就盜那超連結的圖使用吧
理論上,當我們處理recPermute("","ABB");時
也應該是要執行16次
而且因為順序是
ABB
ABB
BAB
BBA
BAB
BBA
若把去除重複排列簡單的理解為記錄上次排列內容
(雖然以程式實作來看這麼理解沒問題)
但可能會不好解釋為什麼這樣削得掉重複排列
這邊順便說一下全排列16次要怎麼算
陣列長度1,2比較例外
陣列長度是1的時候,只有1次,記為T(1),把全排列的陣列長度當作輸入大小
陣列長度是2的時候,1(第一次) + 2(第一個先與第二個先的狀況) + 2*T(2-1) = 1+2*2(1) = 5次
陣列長度是3的時候,1(第一次) + 3(輪流三個最先) + 3*(T(3)-1) = 1+3+3*4 = 16次
最後一個減一的原因是,在計算子情況運行次數時,要去除第一次呼叫遞迴函式才正確
陣列長度是4的時候是65次 = 1 + 4 + 4*15
陣列長度是5的時候是326次 = 1 + 5 + 5*64
6的時候是1957次 = 1+ 6 + 6*325依此類推
回正題:
遞迴,尤其是非尾端遞迴的情況
尾端遞迴長得像
if(...){return 函式自己名稱或常數(...);}else{return 函式自己名稱或常數(...);}
其實非尾端遞迴很像電影《Inception》(台:《全面啟動》,陸:《盜夢空間》)的情節
是由一層一層的夢境所組成的
有時會迷失自己在哪層夢境
為了方便理解
把程式改寫下
void recPermute(string soFar,string rest)
{
static int inception_token = 0;
inception_token++;
string check_repeat="\0";
string next;
if(rest == "") {
cout << soFar << " inception_token " << inception_token << "\n";
} else {
for(int i = 0; i < rest.length(); i++) {
next = soFar + rest[i];
string remaining = rest.substr(0,i) + rest.substr(i+1);
cout << "next " << next << " rest " << remaining << " " << i <<
" inception_token " << inception_token << "\n";
cout << "check_repeat " << check_repeat << " " << i <<
" inception_token " << inception_token << "\n";
if(next != check_repeat)
recPermute(next, remaining);
check_repeat = next;
//寫在最上方也行,不過我覺得寫在後邊比較好理解
//注意,這個是區域變數,在每個遞迴函式中值分別獨立
}
}
}
------------------------------------------
inception_token其實沒作用啦
它只是記錄呼叫遞迴函式的次數
並沒講在第幾層夢境(遞迴)
雖然本來想要達到的效果確實是紀錄在哪一層
不過可以藉由執行次數的結果與上下順序來推斷
觀察後我得到的結論如下圖
其中在第二層中"a"也有被記錄
只是在rec_Permute("b","ab")時因為不重複作用較不明顯
而第三層中"ba"也有被記錄
同樣也是因為沒重複的關係所以沒特別列出來
"bb"其實也有被記錄,只是迴圈正好結束了,程式執行結果看不出來
非尾端遞迴情況是有些複雜的
雖然許多時候程式寫起來意外的簡潔
也可以用很簡單的方式幫助記憶
但若仔細觀察程式執行順序的話
可能會發現些問題
以程式來看:我們確實是記錄上一次的排列
這就是我原先說:
「只跟上次的排列結果比對是否一樣來判斷有沒有重複排列」
的原因
但觀察執行順序,我們比較的準確來說其實是"上一層的排列結果"
注意每一層區域變數是分別獨立的(雖然改成靜態變數依然可以正常運作)
因為遞迴執行順序是後進先出的,跟堆疊一樣
命令式語言處理遞迴也的確是用堆疊(stack)或堆積(heap)來做,兩者差異是記憶體方向不同
若以上一次來解釋的話
第九次執行遞迴時得到"bba"
下次"bab"再跟"bba"比較是否相等
咦,其實不等嘛,照這說法理論上應該要執行第10次
可是實際上程式確實停下來了
其實是因為有層的差異(或者說是遞迴執行順序的關係),是回到第二層("b","ab")
("b","ab")的下次(for(i=0;i<rest.length();i++)中 "i++" 了)
還是("b","ab")
if(next != check_repeat)
recPermute(next, remaining);
所以停止呼叫
由此來看
說跟上一次的排列結果來比也不能算錯
只是感覺有些容易誤導人、沒那麼直觀
所以這裡再講得更清楚些
若上述講得看不懂
大概是我表達能力不好
不過其實不用看懂
記好直接用也是可以的
因為觀察程式執行順序得到的結論
跟用直覺理解的程式寫法是一樣的
就結果論而言兩者並沒有差別
最後說些沒實際生產力的話與些感想
老實說,排列程式以個人來看覺得還蠻難的
(可能也是因為這樣,個人才會一堆題目解不出來嘛)
所以才會像這樣直接找答案
以前在學資料結構時
就曾經在想如何用迴圈寫想很久沒結果
現在還是覺得想出來怎麼寫的人真是天才!!
若覺得排列很簡單的
對岸有個程式題目可以做做看
好像是編程之美一書還是比賽的題目
就是重複排列時
只印出去掉相鄰兩元素相同的狀況
嗯,應該是可以印出所有不重複排列的情況,一個一個檢查把有重複的去掉
可是這樣做也許會超過運行時間(TLE)
而且這麼做其實對於編程者來說沒什麼成長嘛
知乎上已經有解答了
是用動態規劃(Dynamic Programming,常簡稱為DP)
若不知道動態規劃(DP,Dynamic Programming)的話
簡單來說要用動態規劃的題目
分兩步驟,第一步觀察題目導出數學式,第二步再去實作
這有點像解∑1/(k(k+1))這類題目
要先化成∑( (1/k) - (1/(k+1)) )這樣
但是否如此簡單
等碰上時就知道了
因此有很多種動態規劃題目的解法不同
很多程式設計師對於動態規劃有障礙
(碰上個題目自己想出個數學式確實是較困難的)
所以現階段不會的話不用太過難過
(我當然也是其中一個
雖然我不算程式設計師,不過一個人在寫程式時的當下時就可以視為程式設計師)
只是若發現自己不會動態規劃的話
討論程式相關時
就別再說熟能生巧、多做多想等了
雖然講熟能生巧、多做多想的人本身可能會動態規劃
但這是兩回事!!
只講熟能生巧、多做多想
會讓別人以為寫程式就只是刷各類題型而已
或者說會讓人以為程式就像是"只是我不勤勞或我沒學過所以不會"的領域
不過...
話說回來,確實絕大多數的實用程式都只是不勤勞或搜尋引擎搜錯關鍵字的問題
因為寫實用程式大多是靠著前人的勞動結果組合出自己想要的
這邊僅是提下,也有不是的狀況
只是不是的情況以程式競賽、需要些背景知識(像圓與矩形的碰撞判斷、3D程式)的居多
雖然程式競賽、需要些背景知識的程式
有些會有現有函式庫解決,或者是那類情形一般人碰不到
這篇大概就這樣
part 2是解UVa online上的一題
跟淺述Stanford解法、演算法筆記網站的解法異同
(希望今天能處理完解題外的部份,這樣星期天大概就能完成)
 創作內容
創作內容
 單機版網頁遊戲系列相關 (20)
單機版網頁遊戲系列相關 (20)